はじめに
fitbitとは、心拍数、歩数や睡眠をトラッキングするために腕に着用するタイプのスマートウォッチです。ここでは、Fitbit APIを使って一週間分の睡眠データを取得してmatplotlibでまとめて表示する方法を解説します。
手順
APIの登録など
その1を参照してください。

fitbit-pythonのインストールなど
その2を参照してください。
モジュールのインポートなど
バージョン
APIの認証
CLIENT_ID, tokenなどを定義
その1で取得したCLIENT_IDとCLIENT_SECRETとtoken.txtをここで使います。token.txtは実行ファイルと同じ場所に置いておきます。
認証
fitbit.Fitbit()により、認証を行います。updateToken関数はtokenの更新用の関数でrefresh_cb に updateTokenとすることでtokenが期限切れの際に随時更新してくれるようになります。
1週間分のデータの取得
DATE+ dt.timedelta(days=i)で日付を一日単位でずらしながら、client.sleep(DATE_)により睡眠データが入手します。取得したデータはpd.DataFrame.from_dictによりデータフレームにし、リストに格納していきます。
リストの最初のデータフレームは以下のようになっています。
睡眠のレベルを数値化
睡眠のレベルデータを数値データに変換します。
表示範囲の設定
それぞれの日付に対して22:00から8:00までデータを表示するために表示範囲のデータをdatetime形式で作成しておきます。
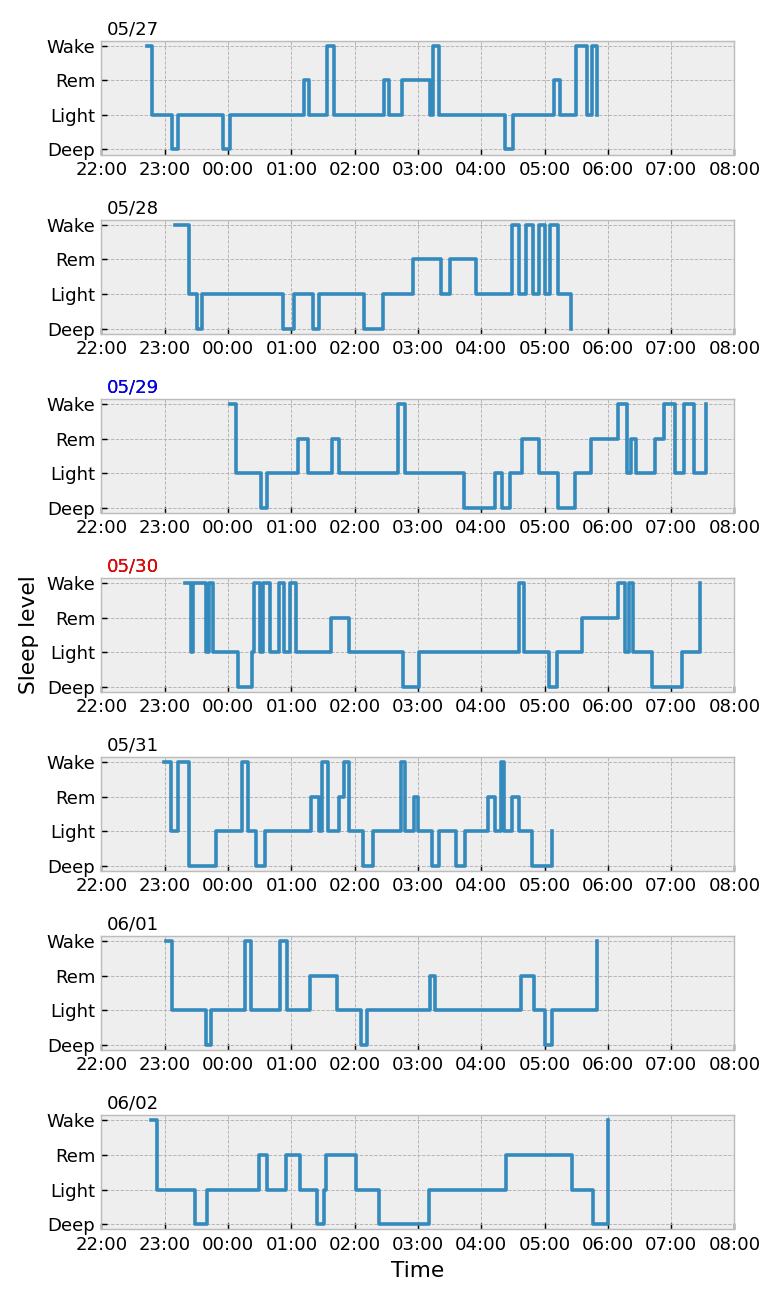
1週間分の睡眠データの表示
ax[i].step()でそれぞれの日の睡眠データを順次プロットしていきます。ax[i].text()でそれぞれのプロットの日付を左上に表示します。ax[i].set_xlim()でx軸の表示範囲を調整します。
全てリスト内包で処理しています。
x軸の表示形式については、mdates.DateFormatter(“%H:%M”)により時間と分の形式で表示できるようになります。
土曜を青、日曜の日付を赤にしています。
参考



コメント