はじめに
lmfitを使ったカーブフィッティングでは、結果のパラメータを効率的に管理・分析するためにPandas DataFrameに変換すると便利です。この記事では、その具体的な方法について解説します。
コード
解説
モジュールのインポートなど
バージョン
データの生成
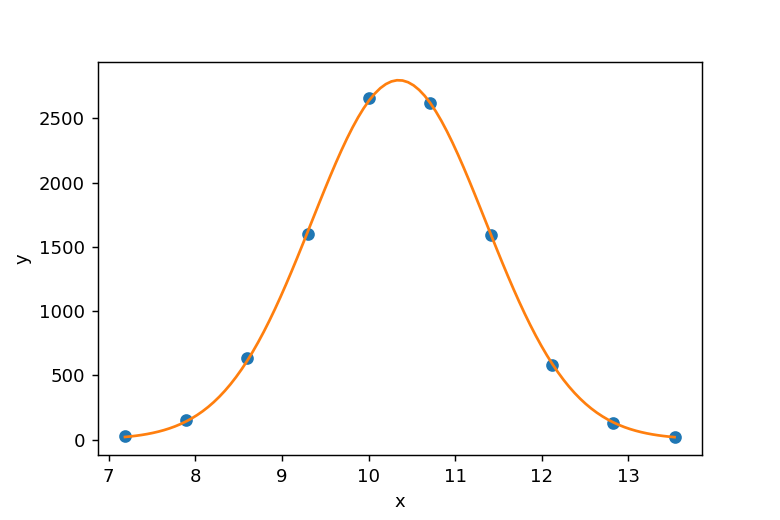
yデータは、default_rng()を用いてrngを初期化し、rng.normal()でガウス分布に従う10,000個のデータを生成してヒストグラム化することで準備しました。xとyの関係は以下の図のようになります。
モデルの定義
lmfit.models の GaussianModelをモデル関数として用います。
初期パタメータの推定
model.guess(y, x=x)を使用して、上図のデータをsin関数モデルで近似するためのフィッティングパラメータの初期値を推定します。得られるパラメータ(params)は以下のようになります。
カーブフィット
model.fit(y, params, x=x)により、カーブフィッティングを実行します。
フィッティング結果の表示
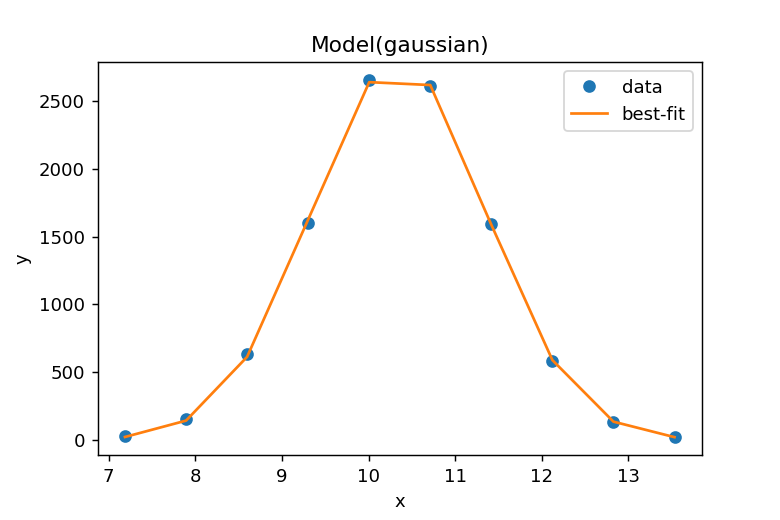
result.plot_fit()を使用するとデータとフィッティングカーブが表示されます。しかし、これではただの折れ線グラフのように見えるため、フィッティングパラメータを取得し、より細かいステップでガウス分布曲線を描画します。
フィッティングパラメータをDataFrameに変換
フィッティングで得られたパラメータはresult.paramsで見ることができます。
これをvaluesdictによって、順序つき辞書に変換します。
辞書型データをDataFrameに変換するには、pd.DataFrame.from_dict()メソッドを使用します。
以下のようなDataFrameが得られます。
| value | |
|---|---|
| amplitude | 7039.668927 |
| center | 10.348919 |
| sigma | 1.004243 |
| fwhm | 2.364810 |
| height | 2796.557201 |
パラメータを使って滑らかなガウス分布曲線を表示
参考

Parameter and Parameters — Non-Linear Least-Squares Minimization and Curve-Fitting for Python
lmfit.github.io


pandas.DataFrame.from_dict — pandas 3.0.1 documentation
pandas.pydata.org
コメント