はじめに
fitbitとは、心拍数、歩数や睡眠をトラッキングするために腕に着用するタイプのスマートウォッチです。日々の健康状態を把握するのにとても役立っています。ここでは、アプリの登録からtokenの取得までを解説したその1の続きとして、Fitbit APIを使って睡眠データを取得してmatplotlibで表示するところまで解説します。
その1はこちら↓です。

手順
fitbit-pythonのインストール
pip install fitbitでfitbit APIをpythonで操作できるモジュールをインストールします。
fitbit-pythonのAPI VERSIONの変更
pip show fitbitでfitbit-pythonがインストールされた場所を確認します。こうすると、Nameやversionなどに加えてLocationの情報が表示されます。locationの場所にあるapi.pyを開いて、
API_VERSION = 1.0を
API_VERSION = 1.2に変更して、保存して閉じます。2箇所あります。
これをすることでWake, Rem, Light, Deepの4段階の睡眠レベルの情報を受け取れるようになります。
モジュールのインポート
これ以降の処理はjupyter lab上で行います。
バージョン
CLIENT_ID, tokenなどを定義
その1で取得したCLIENT_IDとCLIENT_SECRETとtoken.txtをここで使います。token.txtは実行ファイルと同じ場所に置いておきます。
認証
fitbit.Fitbit()により、認証を行います。updateToken関数はtokenの更新用の関数でrefresh_cb に updateTokenとすることでtokenの期限切れの際に随時更新してくれるようになります。
睡眠データの取得
DATEを設定し、client.sleep(DATE)とすることで睡眠データが得られます。
取得したdata_sleep_1をpandasのDataFrameにすると以下のようになります。
| dateTime | level | seconds | |
|---|---|---|---|
| dateTime | |||
| 2021-05-11 23:08:30 | 2021-05-11T23:08:30.000 | wake | 600 |
| 2021-05-11 23:18:30 | 2021-05-11T23:18:30.000 | light | 2850 |
| 2021-05-12 00:06:00 | 2021-05-12T00:06:00.000 | deep | 420 |
| 2021-05-12 00:13:00 | 2021-05-12T00:13:00.000 | light | 2070 |
| 2021-05-12 00:47:30 | 2021-05-12T00:47:30.000 | wake | 330 |
| 2021-05-12 00:53:00 | 2021-05-12T00:53:00.000 | light | 1800 |
| 2021-05-12 01:23:00 | 2021-05-12T01:23:00.000 | rem | 360 |
| 2021-05-12 01:29:00 | 2021-05-12T01:29:00.000 | light | 2220 |
| 2021-05-12 02:06:00 | 2021-05-12T02:06:00.000 | wake | 300 |
| 2021-05-12 02:11:00 | 2021-05-12T02:11:00.000 | light | 1770 |
| 2021-05-12 02:40:30 | 2021-05-12T02:40:30.000 | deep | 720 |
| 2021-05-12 02:52:30 | 2021-05-12T02:52:30.000 | light | 750 |
| 2021-05-12 03:05:00 | 2021-05-12T03:05:00.000 | rem | 1200 |
| 2021-05-12 03:25:00 | 2021-05-12T03:25:00.000 | light | 2880 |
| 2021-05-12 04:13:00 | 2021-05-12T04:13:00.000 | rem | 2190 |
| 2021-05-12 04:49:30 | 2021-05-12T04:49:30.000 | light | 1200 |
| 2021-05-12 05:09:30 | 2021-05-12T05:09:30.000 | deep | 1770 |
| 2021-05-12 05:39:00 | 2021-05-12T05:39:00.000 | light | 30 |
| 2021-05-12 05:39:30 | 2021-05-12T05:39:30.000 | wake | 240 |
| 2021-05-12 05:43:30 | 2021-05-12T05:43:30.000 | light | 1140 |
| 2021-05-12 06:02:30 | 2021-05-12T06:02:30.000 | wake | 270 |
| 2021-05-12 06:07:00 | 2021-05-12T06:07:00.000 | rem | 300 |
| 2021-05-12 06:12:00 | 2021-05-12T06:12:00.000 | wake | 510 |
sleepレベルを数値データに変換
| dateTime | level | seconds | level_int | |
|---|---|---|---|---|
| dateTime | ||||
| 2021-05-11 23:08:30 | 2021-05-11T23:08:30.000 | wake | 600 | 3 |
| 2021-05-11 23:18:30 | 2021-05-11T23:18:30.000 | light | 2850 | 1 |
| 2021-05-12 00:06:00 | 2021-05-12T00:06:00.000 | deep | 420 | 0 |
| 2021-05-12 00:13:00 | 2021-05-12T00:13:00.000 | light | 2070 | 1 |
| 2021-05-12 00:47:30 | 2021-05-12T00:47:30.000 | wake | 330 | 3 |
| 2021-05-12 00:53:00 | 2021-05-12T00:53:00.000 | light | 1800 | 1 |
| 2021-05-12 01:23:00 | 2021-05-12T01:23:00.000 | rem | 360 | 2 |
| 2021-05-12 01:29:00 | 2021-05-12T01:29:00.000 | light | 2220 | 1 |
| 2021-05-12 02:06:00 | 2021-05-12T02:06:00.000 | wake | 300 | 3 |
| 2021-05-12 02:11:00 | 2021-05-12T02:11:00.000 | light | 1770 | 1 |
| 2021-05-12 02:40:30 | 2021-05-12T02:40:30.000 | deep | 720 | 0 |
| 2021-05-12 02:52:30 | 2021-05-12T02:52:30.000 | light | 750 | 1 |
| 2021-05-12 03:05:00 | 2021-05-12T03:05:00.000 | rem | 1200 | 2 |
| 2021-05-12 03:25:00 | 2021-05-12T03:25:00.000 | light | 2880 | 1 |
| 2021-05-12 04:13:00 | 2021-05-12T04:13:00.000 | rem | 2190 | 2 |
| 2021-05-12 04:49:30 | 2021-05-12T04:49:30.000 | light | 1200 | 1 |
| 2021-05-12 05:09:30 | 2021-05-12T05:09:30.000 | deep | 1770 | 0 |
| 2021-05-12 05:39:00 | 2021-05-12T05:39:00.000 | light | 30 | 1 |
| 2021-05-12 05:39:30 | 2021-05-12T05:39:30.000 | wake | 240 | 3 |
| 2021-05-12 05:43:30 | 2021-05-12T05:43:30.000 | light | 1140 | 1 |
| 2021-05-12 06:02:30 | 2021-05-12T06:02:30.000 | wake | 270 | 3 |
| 2021-05-12 06:07:00 | 2021-05-12T06:07:00.000 | rem | 300 | 2 |
| 2021-05-12 06:12:00 | 2021-05-12T06:12:00.000 | wake | 510 | 3 |
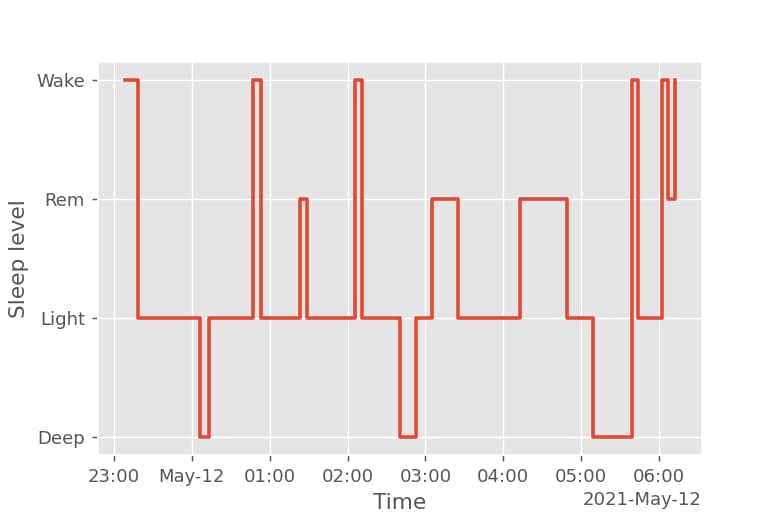
睡眠レベルの経時的な変化を表示
睡眠レベルの経時的な変化をax.stepでステップ状のプロットで表示します。以下の図を作成することができます。
参考



コメント
度々申し訳ございません。
pipでpython3.10ではmatplotlibをインストールできず、python2.7を使おうとしています。
そうしましたら、
py -2.7 -m pip install matplotlib
DEPRECATION: Python 2.7 will reach the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 won’t be maintained after that date. A future version of pip will drop support for Python 2.7. More details about Python 2 support in pip, can be found at https://pip.pypa.io/en/latest/development/release-process/#python-2-support
Requirement already satisfied: matplotlib in c:\python27\lib\site-packages (2.2.5)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in c:\python27\lib\site-packages (from matplotlib) (2.4.7)
Requirement already satisfied: python-dateutil>=2.1 in c:\python27\lib\site-packages (from matplotlib) (2.8.2)
Requirement already satisfied: six>=1.10 in c:\python27\lib\site-packages (from matplotlib) (1.16.0)
Requirement already satisfied: pytz in c:\python27\lib\site-packages (from matplotlib) (2021.3)
Requirement already satisfied: kiwisolver>=1.0.1 in c:\python27\lib\site-packages (from matplotlib) (1.1.0)
Requirement already satisfied: backports.functools-lru-cache in c:\python27\lib\site-packages (from matplotlib) (1.6.4)
Requirement already satisfied: numpy>=1.7.1 in c:\python27\lib\site-packages (from matplotlib) (1.16.6)
Requirement already satisfied: cycler>=0.10 in c:\python27\lib\site-packages (from matplotlib) (0.10.0)
Requirement already satisfied: setuptools in c:\python27\lib\site-packages (from kiwisolver>=1.0.1->matplotlib) (41.2.0)
WARNING: You are using pip version 19.2.3, however version 20.3.4 is available.
You should consider upgrading via the ‘python -m pip install –upgrade pip’ command.
このようなエラーとなってしまい、どちらのバージョンでもインストールできないのですが、どのバージョンでインストールされていますでしょうか。また、2.7か3.10において使用可能になる方法が見つからないのですが、どう対処されていますでしょうか。
python3.10はまだ出たばかりで、対応してないライブラリが多そうですので、python3.9でトライしてみてはいかがでしょうか。
python3.9でトライしたところ成功しました。ありがとうございます。
また、次に実行をしようとしたところ、
KeyError: ‘activities-heart-intraday'(34行目)
このようなエラーとなったのですが、このコードは既に取得しているデータを表示することはできるのでしょうか。
また、この部分で何か手を加えたことがありましたら教えていただけると嬉しいです。度々申し訳ございません。
KeyError: ‘activities-heart-intraday’の原因はアプリケーションのタイプがPersonal以外になっている可能性が高いそうです。
アプリの登録の部分のOAuth 2.0 Application Type(アプリのタイプ)を Personalにし、再度登録してみてください。
参考: https://github.com/pkpio/fitbit-googlefit/issues/2
この部分は完了しました。ありがとうございます。
再度今度は
Traceback (most recent call last):
File “C:\Users\yuuki\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\core\indexes\base.py”, line 3361, in get_loc
return self._engine.get_loc(casted_key)
File “pandas\_libs\index.pyx”, line 76, in pandas._libs.index.IndexEngine.get_loc
File “pandas\_libs\index.pyx”, line 108, in pandas._libs.index.IndexEngine.get_loc
File “pandas\_libs\hashtable_class_helper.pxi”, line 5198, in pandas._libs.hashtable.PyObjectHashTable.get_item
File “pandas\_libs\hashtable_class_helper.pxi”, line 5206, in pandas._libs.hashtable.PyObjectHashTable.get_item
KeyError: ‘time’
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File “c:\Users\yuuki\AppData\Local\Programs\Python\Python39\04e9973678c16de50b5027ba6012c2a5-46b41b8a9cbb22a49e0d179df23b7b57c386b295\heartbeat_fitbit.py”, line 71, in
times = date_ser.str.cat(heart_rat[‘time’],sep=’ ‘)
File “C:\Users\yuuki\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\core\frame.py”, line 3458, in __getitem__
indexer = self.columns.get_loc(key)
File “C:\Users\yuuki\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\core\indexes\base.py”, line 3363, in get_loc
raise KeyError(key) from err
KeyError: ‘time’
このようなtimeについてエラーが出てしまい、検索をかけても全くわからなく、止まっている状態です。このようなエラーは出ましたでしょうか。
エラーはtimes = date_ser.str.cat(heart_rat[‘time’],sep=’ ‘)の部分で出ているようです。str.catはDataFrameの文字列を結合する関数であり、KeyError: ‘time’と出ているので、heart_ratという名前のDataFrameに、timeという名前のカラムがないことが原因と思われます。
手順通りに行ってきたと思いますが、
以下のエラーが出ます。
HTTPUnauthorized: Authorization Error: Invalid authorization token type
この場合、どうしたらよいでしょうか?
アクセストークンが先頭にないとエラーが出るようです。
https://community.fitbit.com/t5/Web-API-Development/Why-occur-error-Invalid-authorization-token-type/m-p/2642197#M9084
考えられる原因としては、token.txtの変な位置に改行が入っている、などでしょうか?
ありがとうございました。
最後まで上手くいきました!
大変遅ればせながら上手く行きました。
curlに不慣れで、\→^に変えたら解決しました。
早々にご回答頂きましてありがとうございました!