はじめに
fitbitとは、心拍数、歩数や睡眠をトラッキングするために腕に着用するタイプのスマートウォッチです。ここでは、Fitbit APIを使って一年分の睡眠時間を取得し、matplotlibのヒストグラムにより表示する方法を解説します。
手順
APIの登録など
その1を参照してください。

fitbit-pythonのインストールなど
その2を参照してください。
モジュールのインポートなど
バージョン
APIの認証
CLIENT_ID, tokenなどを定義
その1で取得したCLIENT_IDとCLIENT_SECRETとtoken.txtをここで使います。token.txtは実行ファイルと同じ場所に置いておきます。
認証
fitbit.Fitbit()により、認証を行います。updateToken関数はtokenの更新用の関数でrefresh_cb に updateTokenとすることでtokenが期限切れの際に随時更新してくれるようになります。
1年分のデータの取得
日付の設定
2020年の最初と最後の日をそれぞれdatetime形式で作成します。
100 日間ごとに日付範囲を分ける
一度に取得することのできる日数は100日までです。100日以上の日付範囲を指定すると、
となります。そこで、以下のコードで100日ごとの日付範囲をタプルで作成します。
睡眠データの取得
client.time_series()によって睡眠データを取得します。base_dateとend_dateに先ほど作成したタプルの値が入るようにfor文を回し、結果をリストに入れていきます。
睡眠データから睡眠時間の抽出
睡眠時間は”duration”の値となります。睡眠データリストの中から、睡眠時間のみを取り出し、睡眠時間リストを作成します。
リストの形状は、365以上のなので、昼寝の分も含まれていると思われます。
1年間の睡眠時間の要約統計量の表示
睡眠時間を時間(hour)に変換し、pandasのdescribeで要約統計量を表示すると以下のようになります。
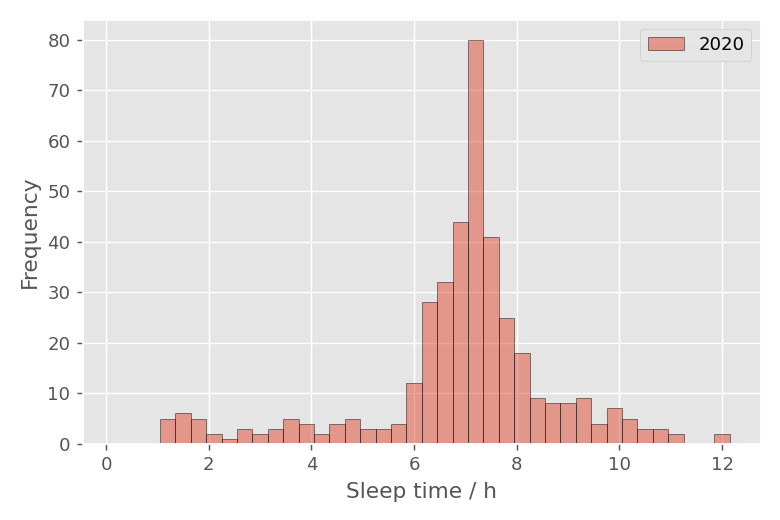
睡眠時間分布をヒストグラムで表示
睡眠時間データに対して、np.histogramでヒストグラムデータを作成し、matplotlibのbarグラフでヒストグラムを作成しました。
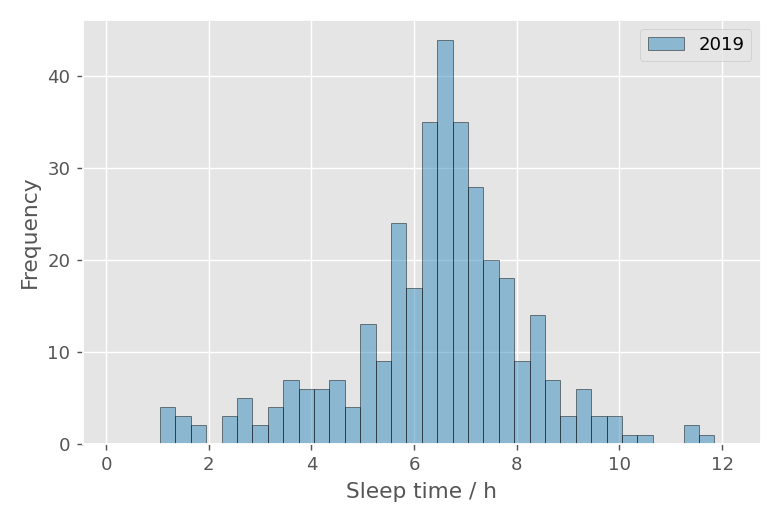
2019年の睡眠時間ヒストグラム
同様の方法で2019年の睡眠時間ヒストグラムを作成すると以下のようになります。
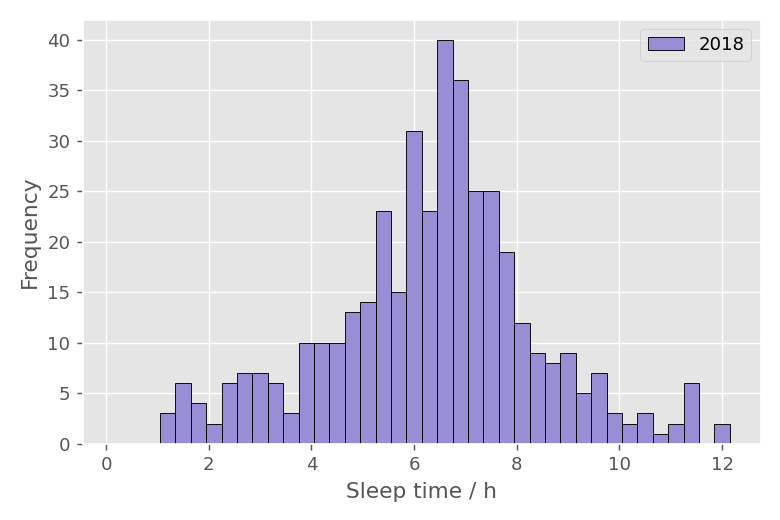
2018年の睡眠時間ヒストグラム
2018年の睡眠時間ヒストグラムは以下のようになります。
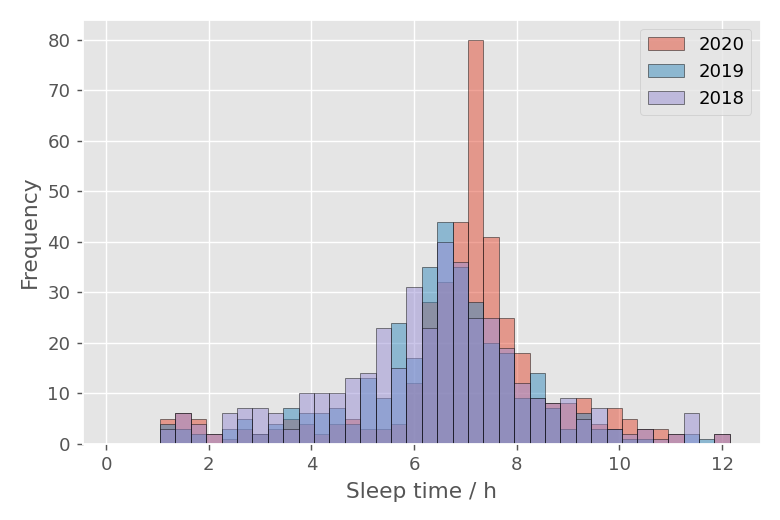
睡眠時間ヒストグラムをまとめて表示
2018年から2020年のヒストグラムをまとめて表示すると以下のようになります。
参考




コメント