はじめに
この記事では、lmfitライブラリを使用する際に、データセット内にNaN(欠損値)が含まれている場合の処理方法について解説します。lmfitは非線形最小二乗法によるカーブフィッティングを行うためのPythonライブラリで、Scipy.optimize.curve_fitの機能を拡張したものです。NaNの扱い方によってフィッティング結果が変わるため、適切な処理方法を選択することが重要です。
lmfitにおけるNaN処理オプション
lmfitでは、Modelクラスのfitメソッドにnan_policyパラメータを指定することで、NaN値の処理方法を制御できます。このパラメータには以下の3つのオプションがあります:
‘raise’(デフォルト)
データにNaNが含まれている場合、エラーを発生させます。これはデフォルトの動作であり、データの問題を早期に検出するのに役立ちます。
# NaNが含まれているとエラーが発生
result = model.fit(data, params, x=x, nan_policy='raise')‘omit’
NaNを含むデータポイントを計算から除外します。これにより、有効なデータポイントのみを使用してフィッティングが行われます。
# NaNを含むデータポイントを除外してフィッティング
result = model.fit(data, params, x=x, nan_policy='omit')‘propagate’
NaNをそのまま計算に含め、伝播させます。この場合、NaNを含む計算結果もNaNとなり、最終的な残差計算にも影響します。
# NaNをそのまま伝播させる
result = model.fit(data, params, x=x, nan_policy='propagate')以下では実際の例を示していきます。
コード
解説
モジュールのインポートなど
バージョン
関数の定義
指数関数的減衰関数を定義します。
データの生成
np.linspace(0, 10, num=1000)関数を使用して1000個のデータポイントを生成し、これを関数に入力してデータセットを作成しました。np.random.randn(t.size)/2を適用してノイズを加え、その後、データの一部を意図的にNaN値に置き換えました。
nan_policy=”raise”でフィッティング
データにNaNがあるので、ValueErrorが返ってきます。
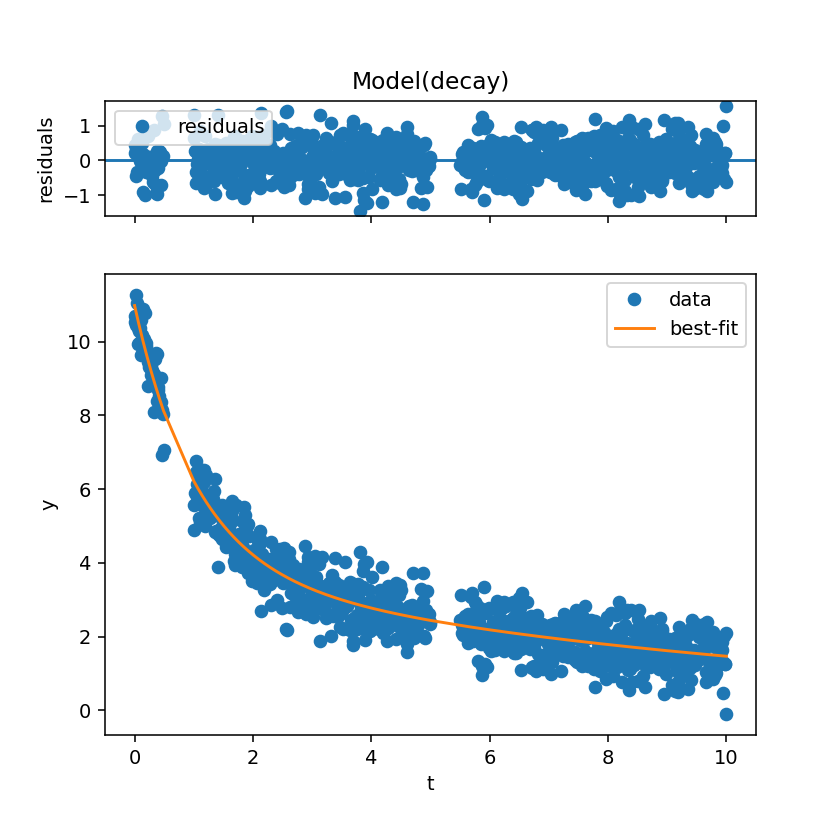
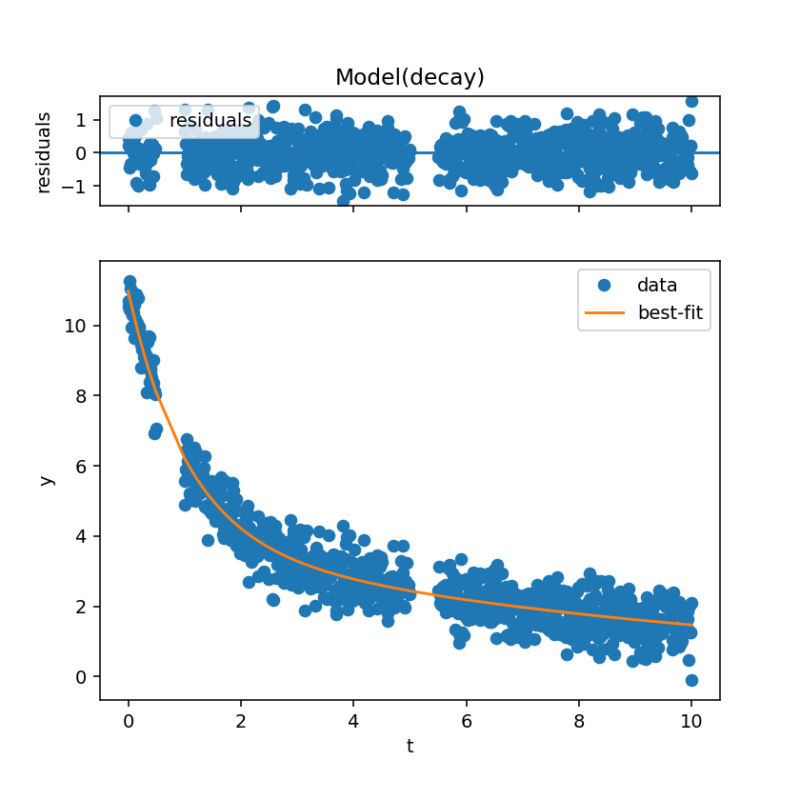
nan_policy=’omit’でフィッティング
NaNを除外したデータでフィッティングが行われます。
結果を図示すると以下のようになります。
nan_policy=’propagate’でフィッティング
フィッティングは実行されず、パラメータは初期値のまま変化しません。
コードをダウンロード(.pyファイル) コードをダウンロード(.ipynbファイル)まとめ
lmfitでNaNを含むデータをフィッティングする際、nan_policyパラメータを適切に設定することが重要です。データの性質や分析の目的に応じて、最適な処理方法を選択しましょう。
・‘raise’: データの品質を重視し、NaNを事前に処理したい場合
・‘omit’: 利用可能なデータを最大限活用し、欠損値を無視したい場合
・‘propagate’: NaNの影響を追跡し、特定のワークフローに対応する場合
適切なNaN処理方法を選択することで、より信頼性の高いモデルフィッティング結果を得ることができます。
参考



コメント