はじめに
このページでは、NumPyを使用して正規分布のデータからヒストグラムを作成し、そのヒストグラムの情報から元のデータを再構築する方法について解説します。
コード
解説
モジュールのインポートなど
バージョン
正規分布データの生成
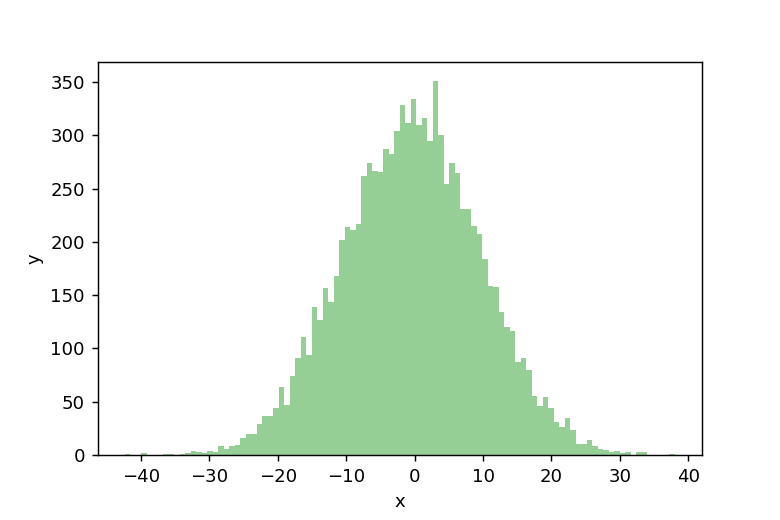
まず、np.random.normal(0, 10, 10000)を使用して、平均0、標準偏差10の正規分布に従うデータを10,000個生成します。
次に、np.histogram(data, bins=100)でこのデータからヒストグラムを作成します。このヒストグラムを図示すると以下のようになります。
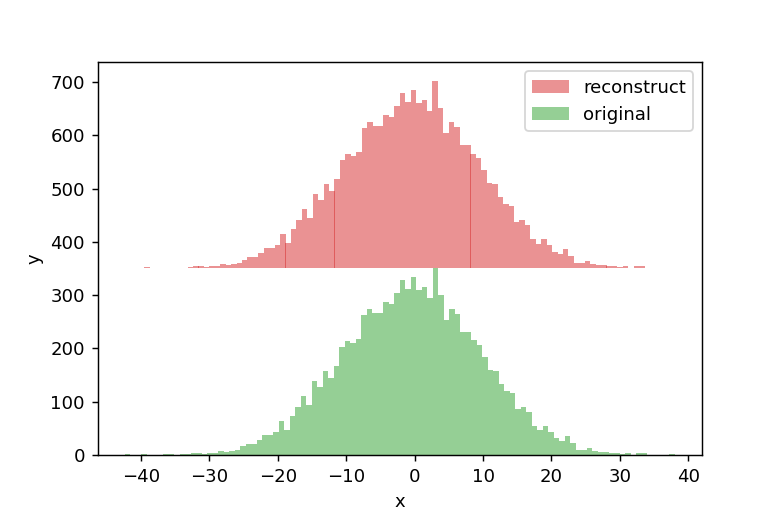
ヒストグラムからのデータ再構築
まず、ヒストグラムの値が0より大きい部分のみを抽出します。このとき、各ビンには幅の半分を加算しておきます。
次に、np.ones(histo_re[i])を使って各ビンの頻度に応じた要素数の配列を作成し、それにbins_re値を掛けることでデータ値を得ます。これらの値を、あらかじめ用意した空のnp.arrayに順次格納していきます。
このようにして再構築した配列の形状と要素の種類は以下の通りです。
再ヒストグラム化
再構築したデータを再びヒストグラム化して表示すると、以下のようになります。
参考

numpy.histogram — NumPy v2.4 Manual
numpy.org


numpy.random.normal — NumPy v2.4 Manual
numpy.org

numpy.ones — NumPy v2.4 Manual
numpy.org
コメント