はじめに
この記事では、pandasのデータフレームにおける中央値のインデックスを求める方法について解説します。データセットの中央に位置する値を特定するための効率的な手法を紹介し、実際のコード例を通して実装方法を示します。
コード
要素数が偶数個の場合
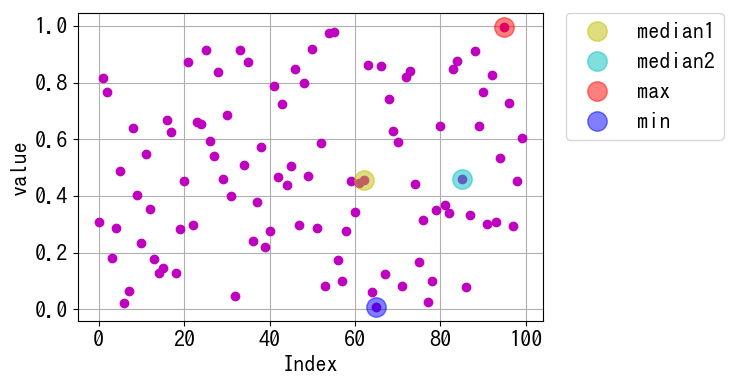
要素数が奇数個の場合
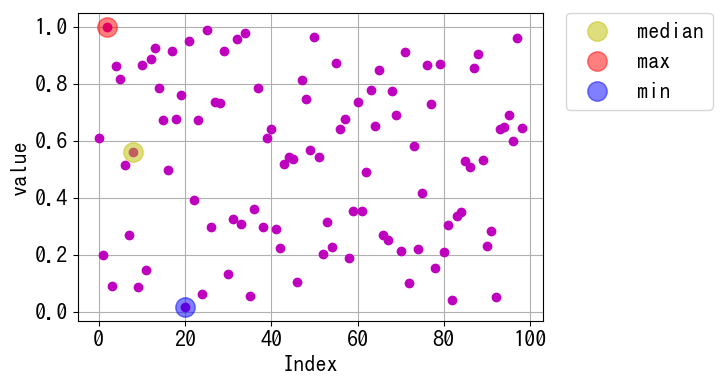
解説
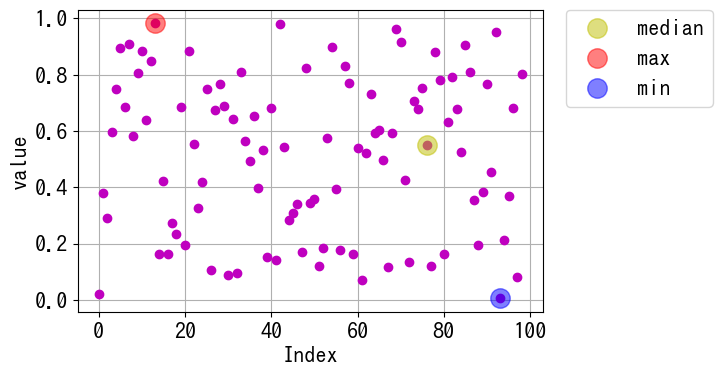
要素数が偶数個の場合
モジュールのインポート
notebookに表示される最大行数を、pd.set_option(‘display.max_rows’, 20)を使用して20行に設定している。
データの生成
numpy.random.rand(n) で 0 から 1 の乱数を n 個生成します。ここでは n=100 なので、100個の乱数が生成されます。この生成したデータを DataFrame 化しました。
中央値のインデックスをもとめる
まず、データから中央値を引いた値の絶対値を計算し、中央値との差が最小となる配列を作成します。その後、.values メソッドを使用して、その配列を NumPy 配列(np.array)に変換します。
要素数が偶数の場合、中央値は2つの中央値の平均となります。これらの中央値のインデックスを求めるには、np.argpartitionを使用します。具体的な使用例は以下を参照してください。

np.argpartition(d_m, 2, axis=0)を使用すると、最も小さい要素のインデックスを2個、配列の左側に配置した配列が生成されます。そのため、[0]と[1]の位置にある要素が中央値のインデックスとなります。
最大値、最小値のインデックス
最大値、最小値のインデックスはそれぞれ、idxmax()、idxmin()メソッドで取得できます。
図示
ax.plot(data.index[m1_ind], data.loc[m1_ind], ‘yo’, markersize=14, alpha=0.5, label=’median1′)のように、マーカーサイズを大きくし透明度を0.5に設定することで、図中のどの点が中央値かを視覚的に分かりやすく表示しています。
凡例は plt.legend(bbox_to_anchor=(1.05, 1), loc=’upper left’, borderaxespad=0) と設定することで、グラフの枠外に配置しています。
bbox_to_anchor は凡例の相対的な位置を設定するパラメータで、グラフの枠の左下を(0,0)、右上を(1,1)とした座標系で指定します。loc は凡例のどの部分をその座標に合わせるかを決める設定で、この例では凡例の左上が(1.05,1)の位置に来るように設定しています。borderaxespad はグラフと凡例の間の余白を調整するパラメータです。
要素数が奇数個の場合
要素数が奇数個の場合、中央値は一つになります。他にも、np.where()関数を使った求め方があります。特に中央値が複数存在する場合は、np.where()を使用する方が効果的です。
まとめ
pandasで中央値のインデックスを求める方法を解説しました。median()関数で中央値を求め、その値にマッチするインデックスを取得する方法や、より複雑なケースでの対応方法についても紹介しました。これらの手法を活用することで、データ分析における中央傾向の把握がより効果的になります。
参考


コメント