はじめに
Pythonのデータ分析ライブラリであるpandasを使って、大量データの取り扱いについて解説します。特に、100万行という規模の1次元データをCSVファイルから効率的に読み込む方法に焦点を当て、実践的なアプローチを紹介します。大規模データセットを扱う際のパフォーマンスの問題や最適化テクニックについても触れていきます。
解説
モジュールのインポート
バージョン
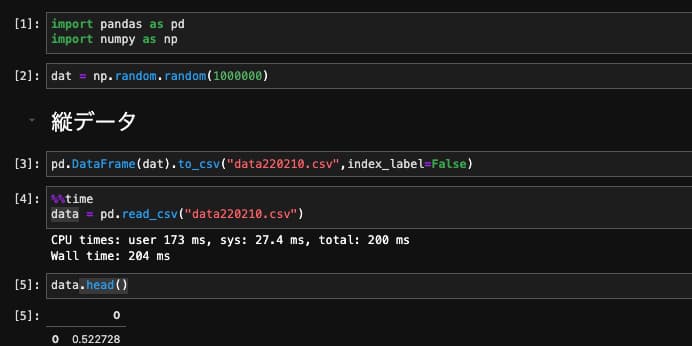
データの生成
1,000,000個のデータをnumpy配列で作成しました。
データの保存
index_label=Falseとして、データだけを保存します。
データの読み込み
pd.read_csv(“fileのパス”)で読み込むことができます。読み込み時間は0.204 sでした。
縦データの先頭5行を表示
先頭の5行をhead()で表示すると以下のようになります。
| 0 | |
|---|---|
| 0 | 0.522728 |
| 1 | 0.136164 |
| 2 | 0.099355 |
| 3 | 0.648669 |
| 4 | 0.326723 |
データを横にして保存
DataFrameを.Tで転置して保存します。
横データの読み込み
横データの場合、読み込みに26秒もかかります。これは縦データと比較して127倍も遅いです。横データの場合に読み込みが遅くなる理由として、以下のようなことが考えられます:
- データ構造の違い – 縦データ(列指向)は連続的にメモリにアクセスできるのに対し、横データ(行指向)は不連続なメモリアクセスが必要になります
- メモリ効率 – pandasのDataFrameは内部的に列単位で最適化されているため、横に長いデータは効率が悪くなります
- パース処理 – 横データでは1行に多数の値があり、CSVパーサーの処理負荷が高くなります
- キャッシュミス – 横データの処理ではCPUキャッシュの効率が下がり、メモリからのデータ取得に時間がかかります
このような要因が組み合わさって、横データの読み込みが縦データと比較して著しく遅くなっていると考えられます。
横データの先頭5列を表示
ilocで先頭の5列を表示すると以下のようになります。
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 0.522728 | 0.136164 | 0.099355 | 0.648669 | 0.326723 |
まとめ
本記事では、pandasのpd.read_csv関数を使って100万個の1次元データを効率的に読み込む方法について解説しました。適切なオプション設定によりメモリ使用量を抑えつつ、大規模データの取り扱いが可能になります。データ分析において大量データを扱う際の基本的なテクニックとして参考にしてください。
参考

pandas.read_csv — pandas 3.0.1 documentation
pandas.pydata.org

pandas.DataFrame.to_csv — pandas 3.0.1 documentation
pandas.pydata.org

コメント