はじめに
この記事では、Jupyter環境でipywidgetsのDropdownウィジェットを使って、異なるデータセットを選択し、そのヒストグラムをリアルタイムで表示する方法を解説します。
matplotlibの場合
コード
解説
モジュールのインポートなど
Jupyter Labでインタラクティブな操作を行うには、コードの冒頭で「%matplotlib widget」と記述します。
Jupyter Notebookの場合は「%matplotlib notebook」を使用します。
標準のGUIを使って別ウィンドウで表示したい場合は、「%matplotlib」と指定します。
バージョン
データの作成
np.logspace(3,5,3)を使用すると、[1000, 10000, 100000]の配列を生成できます。
np.random.normal(0,1,i)は、平均値0、標準偏差1の正規分布に従う乱数をi個生成します。
ヒストグラムデータの作成
np.histogramを使用して、ヒストグラムのheightとbinデータを生成します。これらのデータはそれぞれ空のリストに格納します。
Dropdownの設定
optionsに[(‘data1’, 0), (‘data2’, 1), (‘data3’, 2)]のように指定すると、「data1」を選択した際に値「0」が返されます。valueパラメータは初期選択値を設定します。
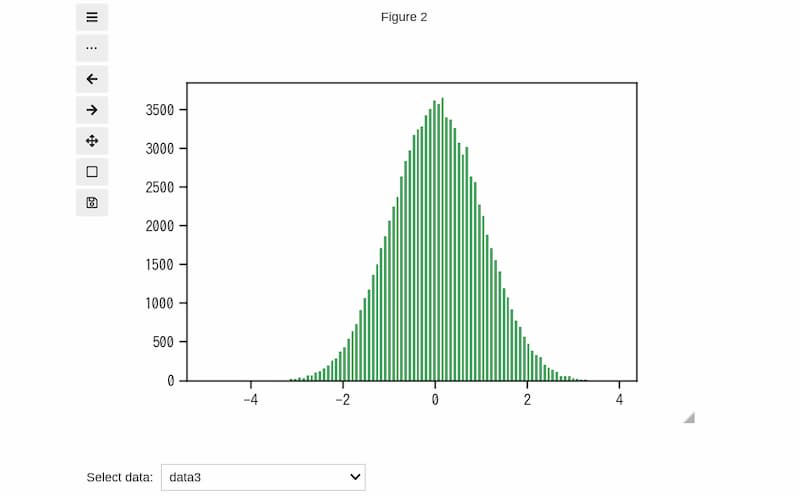
@interactデコレータを使用してipywidgetsを有効化します。 関数f(dd)はドロップダウンの選択が変更されるたびに実行されます。 ユーザーが「data1」などのオプションを選択すると、まずax.cla()で図をクリアし、次にバー間のすきまが生じないようwidthを調整してから、ax.bar関数で選択されたデータのヒストグラムを表示します。例えば、データ数1000の「data1」のヒストグラムは下図のように表示されます。
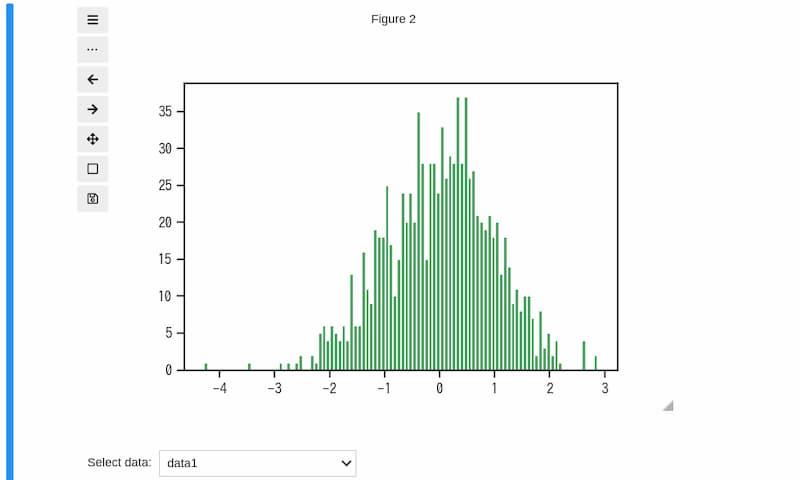
data2の場合
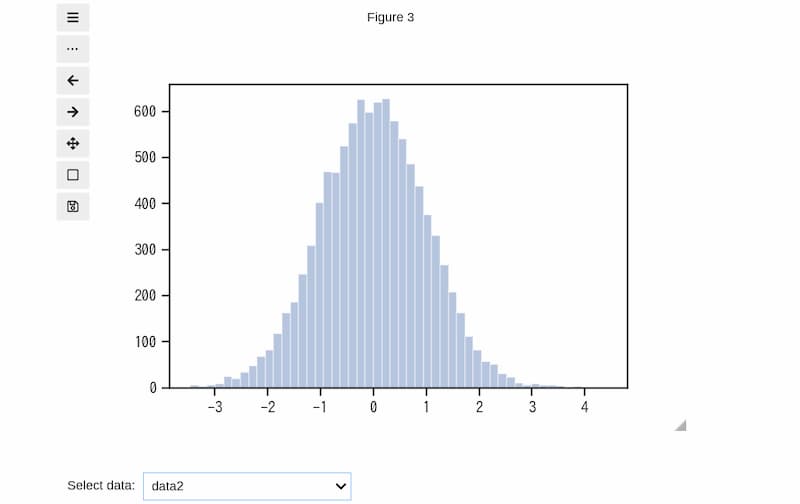
データ数が1万の「data2」のヒストグラムは下図のように表示されます。
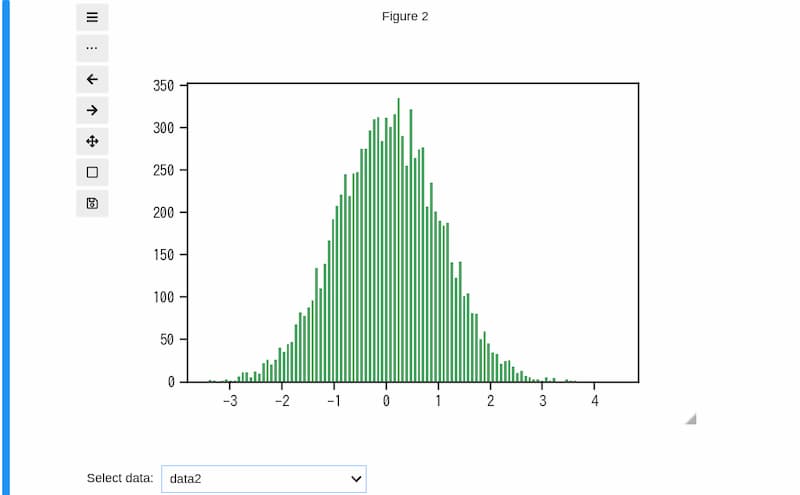
data3の場合
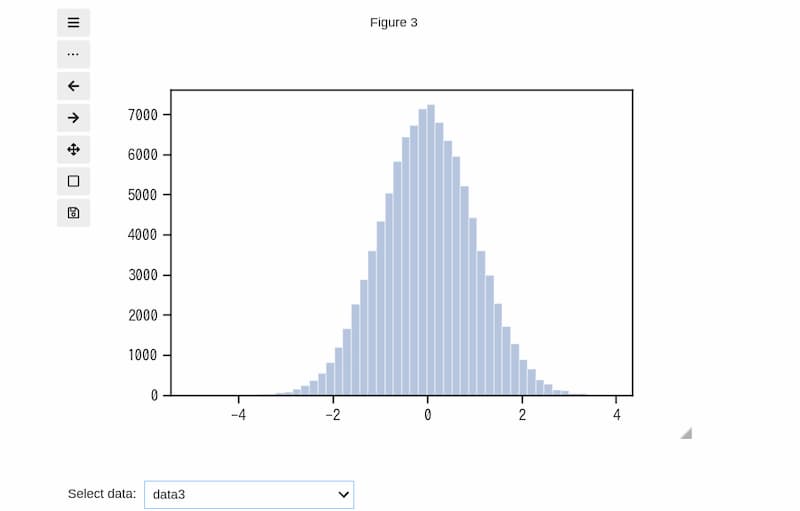
データ数が10万の「data3」のヒストグラムは下図のように表示されます。
seabornの場合
コード
解説
Dropdownの設定
Dropdownの設定はmatplotlibの場合と同様に行います。
distplotでヒストグラムを表示
最初に空のdistplotリストを作成します。 リストの長さが1以上の場合のみaxx.pop().remove()を実行して図を初期化します。これにより、既存の図がある場合にクリアされます。 次に、ユーザーが選択したデータでsns.distplotを作成し、そのdistplotをリストに追加することで図を表示します。
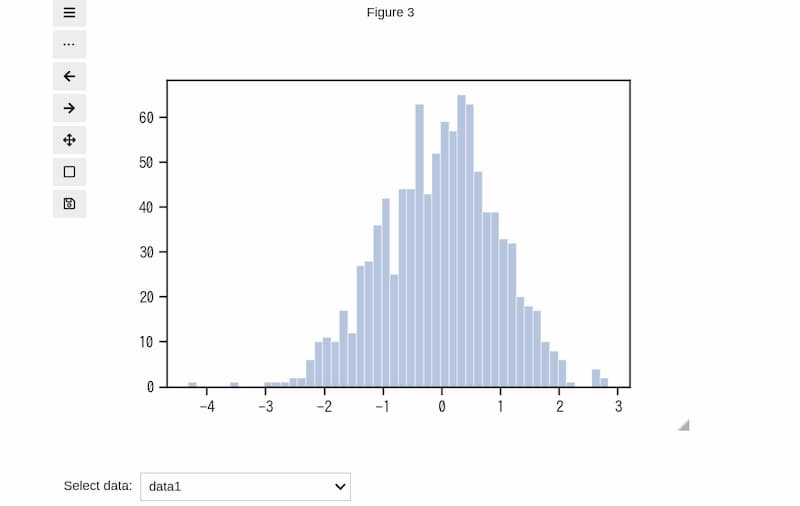
データ数1000のdata1のヒストグラムは以下のように表示されます。
data2の場合
データ数が1万の「data2」のヒストグラムは下図のように表示されます。
data3の場合
データ数が10万の「data3」のヒストグラムは下図のように表示されます。
参考



コメント