はじめに
この記事では、lmfitライブラリを使用した混合モデルによるカーブフィッティングについて解説します。特に複数の関数(例:ガウス関数)を組み合わせてモデルを作成する際に、パラメータ名の重複を避けるためのprefixの使い方に焦点を当てています。実装例を通じて、データの生成、モデルの作成、パラメータの初期値設定、フィッティングの実行、そして結果の可視化までの一連の流れを示します。
コード
解説
モジュールのインポートなど
バージョン
ガウス分布データの生成
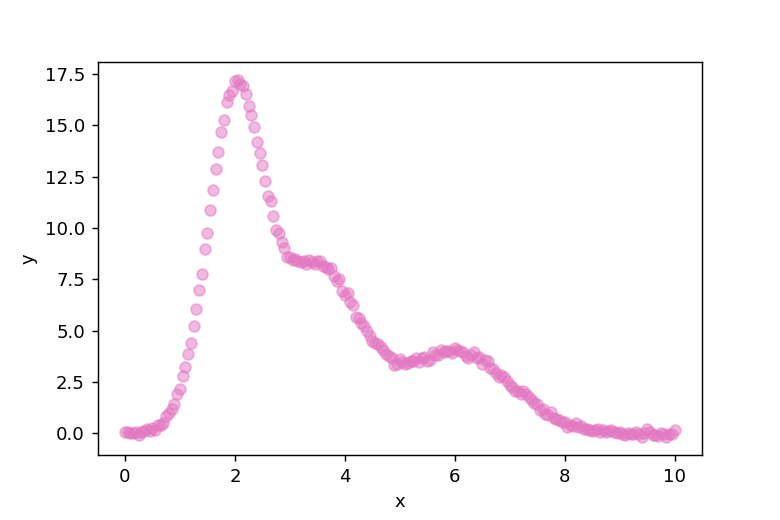
3つのガウス関数を重ね合わせてデータを作成しました。np.random.normal()を使用してデータにランダムなばらつきを追加しています。このデータを図示すると以下のようになります。
パラメータの設定
1つ目
モデルを定義する際、GaussianModel(prefix=’g1_’)のようにprefixを設定すると、パラメータ名の先頭に”g1_”が付加されます。gauss1.guess(data, x=x)を使用して初期パラメータを自動推定し、pars[‘g1_center’].set(value=2, min=1, max=3)のように具体的な値や制約を設定できます。これらの設定後、パラメータ値は以下のようになります。
同様にして2つ目、3つ目の分布のパラメータ設定も行います。
2つ目
3つ目
pars.updateによりパラメータの追加が行われていることがわかります。
カーブフィット
モデルは
mod = gauss1 + gauss2 + gauss3のように定義し、mod.fit(data, pars, x=x)を実行してフィッティングを行います。フィッティング完了後、得られたパラメータ値は次のようになります。
フィッティング結果の表示
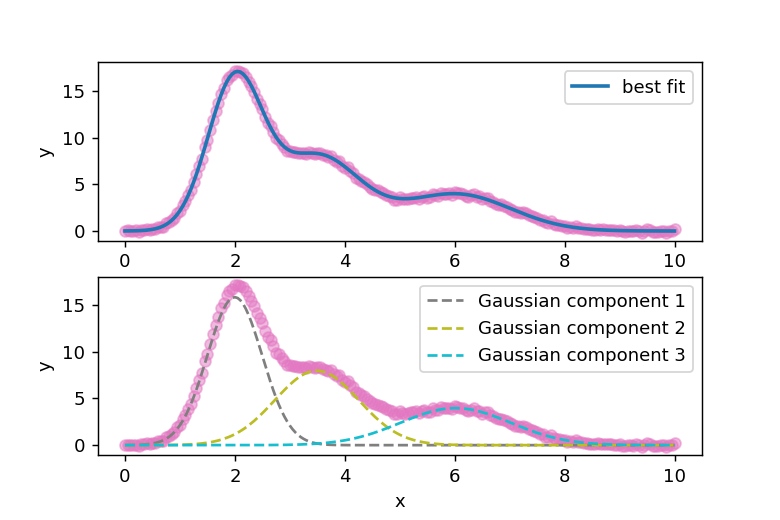
ベストフィットパラメータは result.best_values[‘パラメータ名’] で取得できますが、より簡便な方法として result.eval_components(x=x) があります。この方法では各モデルのフィッティング結果を個別に分離でき、plot(x, comps[‘g1_’]) のような記述で各成分のフィッティングカーブを別々にプロットできます。
まとめ
lmfitの混合モデルとprefixを使うことで、複雑なデータに対しても柔軟にフィッティングを行うことができます。特に、複数のピークを持つスペクトルデータなどの解析に非常に有効です。
参考



コメント
[…] Least-Squares Minimization and Curve-Fitting for Python サボテンパイソン [lmfit] 5. 混合モデルによるカーブフィッティング(prefixの使い方) […]