はじめに
Webスクレイピングは、Webページから必要な情報を自動的に取得する技術です。pandasライブラリを使うことで、WebページのHTMLテーブルを簡単にDataFrameとして取得し、データ分析することができます。本記事では、複数のWebページから複数のテーブルを取得し、それらのデータを集計する方法について解説します。
ここでは、例として、2019シーズンのサッカーくじtotoの結果を利用します。
解説
モジュールのインポート
webページからTableを読み込む
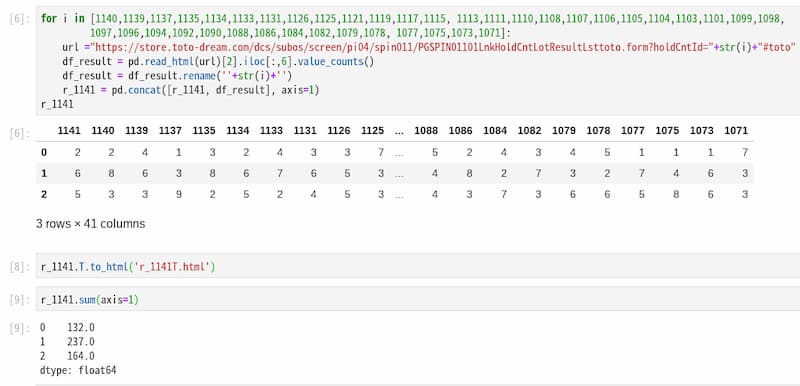
URLに読み込みたいテーブルが存在するウェブページのURLを記載します。テーブルの読み込みは、pd.read_html(URL)で実行できます。この関数はDataFrameのリストを返すため、リストをスライスして希望のテーブルを取得します。ここで取得したテーブルは下記のようになります。
| 開催日 | 競技場 | 予想チーム | |||||
|---|---|---|---|---|---|---|---|
| 開催日 | 競技場 | No | ホーム | 試合結果 | アウェイ | くじ結果 | |
| 0 | 12/07 | 埼玉 | 1 | 浦和 | 2-3 | G大阪 | 2 |
| 1 | 12/07 | アイスタ | 2 | 清水 | 1-0 | 鳥栖 | 1 |
| 2 | 12/07 | 豊田ス | 3 | 名古屋 | 0-1 | 鹿島 | 2 |
| 3 | 12/07 | 札幌ド | 4 | 札幌 | 1-2 | 川崎 | 2 |
| 4 | 12/07 | Eスタ | 5 | 広島 | 1-0 | 仙台 | 1 |
| 5 | 12/07 | ノエスタ | 6 | 神戸 | 4-1 | 磐田 | 1 |
| 6 | 12/07 | 日産ス | 7 | 横浜M | 3-0 | F東京 | 1 |
| 7 | 12/07 | サンアル | 8 | 松本 | 1-1 | 湘南 | 0 |
| 8 | 12/07 | 昭和電ド | 9 | 大分 | 0-2 | C大阪 | 2 |
| 9 | 12/08 | とうスタ | 10 | 福島 | 1-2 | 群馬 | 2 |
| 10 | 12/08 | 藤枝サ | 11 | 藤枝 | 1-0 | 北九州 | 1 |
| 11 | 12/08 | いわスタ | 12 | 岩手 | 1-1 | 讃岐 | 0 |
| 12 | 12/08 | 長野U | 13 | 長野 | 1-0 | 熊本 | 1 |
くじ結果の集計
くじ結果は一番右の列のデータなので、ilocを使ってそのデータをSeriesとして取得します。ilocを使ったデータの取得方法については、下記で詳しく解説しています。
ここでは、得られたSeriesに対して、value_countsを用いて要素のカウントを行った。
得られたSeriesはマルチインデックスを持つため、そのままDataFrameに変換するとデータ選択が複雑になります。そこで先にカラム名を変更しておきましょう。変更は r_1141.rename(‘1141’) のように行えます。
このSeriesである r_1141 を pd.DataFrame(r_1141) でDataFrameに変換すると、以下のようになります。
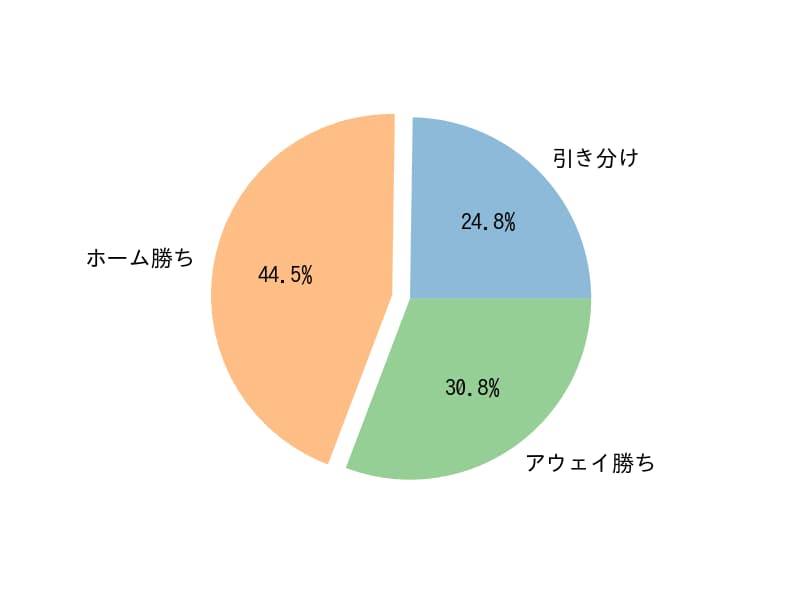
なお、結果の値は 0が引き分け、1がホームチームの勝ち、2がアウェイチームの勝ちを表しています。
| 1141 | |
|---|---|
| 1 | 6 |
| 2 | 5 |
| 0 | 2 |
for文による繰り返しによるデータの取得
上記のデータは1141回目のtotoの結果ですが、次に2019シーズンの他の回のtotoの結果も取得します。
回数に該当する部分を +str(i)+ として置き換えることで、異なるwebページから情報を選択できます。 このようにして取得したデータは pd.concat([r_1141, df_result], axis=1) のように連結し、データを追加していきます。 concatを使ったデータ結合方法については下記で詳しく説明しています。
最終的に得られるTableは下記のようになります。縦長グラフとして見やすくするため、.Tで転置したDataFrameを表示しています。
| 0 | 1 | 2 | |
|---|---|---|---|
| 1141 | 2.0 | 6.0 | 5.0 |
| 1140 | 2.0 | 8.0 | 3.0 |
| 1139 | 4.0 | 6.0 | 3.0 |
| 1137 | 1.0 | 3.0 | 9.0 |
| 1135 | 3.0 | 8.0 | 2.0 |
| 1134 | 2.0 | 6.0 | 5.0 |
| 1133 | 4.0 | 7.0 | 2.0 |
| 1131 | 3.0 | 6.0 | 4.0 |
| 1126 | 3.0 | 5.0 | 5.0 |
| 1125 | 7.0 | 3.0 | 3.0 |
| 1121 | 3.0 | 8.0 | 2.0 |
| 1119 | 5.0 | 6.0 | 2.0 |
| 1117 | 4.0 | 7.0 | 2.0 |
| 1115 | 4.0 | 3.0 | 6.0 |
| 1113 | 4.0 | 4.0 | 5.0 |
| 1111 | 4.0 | 5.0 | 4.0 |
| 1110 | 4.0 | 8.0 | 1.0 |
| 1108 | 1.0 | 7.0 | 5.0 |
| 1107 | 4.0 | 6.0 | 3.0 |
| 1106 | NaN | 6.0 | 7.0 |
| 1105 | 4.0 | 8.0 | 1.0 |
| 1104 | 5.0 | 6.0 | 2.0 |
| 1103 | 1.0 | 5.0 | 7.0 |
| 1101 | 2.0 | 8.0 | 3.0 |
| 1099 | 4.0 | 6.0 | 3.0 |
| 1098 | 4.0 | 6.0 | 3.0 |
| 1097 | 5.0 | 6.0 | 2.0 |
| 1096 | 2.0 | 7.0 | 4.0 |
| 1094 | 4.0 | 5.0 | 4.0 |
| 1092 | 2.0 | 8.0 | 3.0 |
| 1090 | 2.0 | 8.0 | 3.0 |
| 1088 | 5.0 | 4.0 | 4.0 |
| 1086 | 2.0 | 8.0 | 3.0 |
| 1084 | 4.0 | 2.0 | 7.0 |
| 1082 | 3.0 | 7.0 | 3.0 |
| 1079 | 4.0 | 3.0 | 6.0 |
| 1078 | 5.0 | 2.0 | 6.0 |
| 1077 | 1.0 | 7.0 | 5.0 |
| 1075 | 1.0 | 4.0 | 8.0 |
| 1073 | 1.0 | 6.0 | 6.0 |
| 1071 | 7.0 | 3.0 | 3.0 |
データの集計
.sum(axis=1)で0,1,2それぞれの合計値を取得することができます。
結果の表示
まとめ
本記事では、pandasを使用して複数のWebページからテーブルデータを取得し、集計する方法を紹介しました。pd.read_html()関数を活用することで、HTMLテーブルを簡単にDataFrameとして読み込むことができ、そのデータに対して様々な分析や集計を行うことができます。この方法は、Webから定期的にデータを収集し分析する必要がある場合に特に有用です。
参考



コメント