はじめに
複数のエクセルファイルを一つにまとめなければならないケースは、業務やデータ分析の場面でしばしば発生します。手作業でコピーして貼り付ける方法もありますが、ファイル数が多くなると非常に手間がかかります。本記事では、Pythonのpandasライブラリを使って、複数のエクセルファイルを効率的に一つのファイルにまとめる方法を解説します。globモジュールでファイルを選択し、pandasのconcatでデータを結合する基本的な手順を説明します。
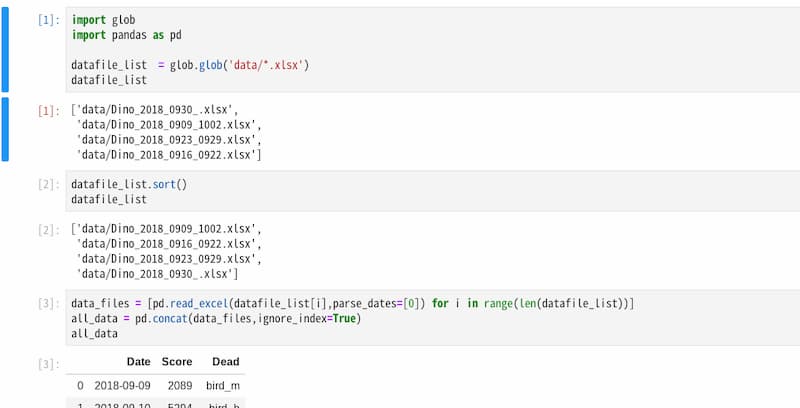
データはchromeの恐竜ゲームの結果で、以下のような形式のエクセルファイルを用いる。恐竜ゲームについては、オフラインでもchrome://dinoにアクセスすれば遊べます。
| Date | Score | Dead | |
|---|---|---|---|
| 0 | 2018-09-09 | 2089 | bird_m |
| 1 | 2018-09-10 | 5294 | bird_h |
| 2 | 2018-09-11 | 6588 | sabo_4 |
| 3 | 2018-09-12 | 8901 | sabo_2 |
| 4 | 2018-09-13 | 7159 | bird_m |
コード
コードをダウンロード(.pyファイル) コードをダウンロード(.ipynbファイル)解説
globでファイル名のリストを取得
glob.glob(filepath)の filepath に、ワイルドカード()を含んだ “data/.xlsx” を指定することで、data フォルダ内にある「任意の文字列.xlsx」という形式のファイルをすべて取得できます。つまり、xlsx 形式のファイルをすべて選択することができます。
ファイル名のソート
.sort()で得られたリストを昇順にソートします。
リスト内包表記のfor文で
pandasのread_excelをdatafile_listの数(len(datafile_list)=4)だけ繰り返します。これによりDataFrameを要素として持つリストが生成されます。
pandasのconcatで結合
pandasの
concat関数を使って各データを連結できます。連結したデータは、リストの最初のデータが先頭に、最後のデータが末尾に配置されます。
ignore_index=Trueを設定すると、元のインデックスは保持されず、新しく連番のインデックスが付与されます。
出来上がるデータは以下のようになります。
タブ区切りテキスト形式で保存
データフレームはto_csvメソッドで保存できます。例えば「all_data.tsv」というファイル名で保存できます。
sepパラメータはデータの区切り文字を指定します。sep='\\t'でタブ区切り、指定しない場合はデフォルトでカンマ区切りになります。
インデックスが不要な場合はindex=Falseを指定することでインデックスを除外して保存できます。
日本語データを含む場合はencoding="shift_jis"を追加することで、日本語を正しく保存できます。
エクセル形式で保存
DataFrameオブジェクト.to_excel()メソッドでエクセル形式で保存できます。ファイル名は”all_data.xlsx”などと指定します。インデックスが不要な場合は、index=Falseと設定することでインデックスを除外して保存できます。
まとめ
本記事では、Pythonのpandasライブラリを使って複数のエクセルファイルを一つにまとめる方法を紹介しました。globでファイルの一覧を取得し、pandasのDataFrameとして読み込み、concatで結合することで効率的にファイルをまとめることができます。この方法により、手作業による時間のかかる作業を自動化でき、大量のデータファイルを扱う業務を効率化することができます。
参考




コメント