はじめに
scikit-learnのmake_classification関数を使用して分類用データを生成する方法について解説します。この関数はガウス分布に基づいたデータポイントを生成し、機械学習アルゴリズムのテストや検証に役立ちます。各種パラメータがデータの特性にどのように影響するかを詳しく見ていきます。
解説
モジュールのインポートなど
バージョン
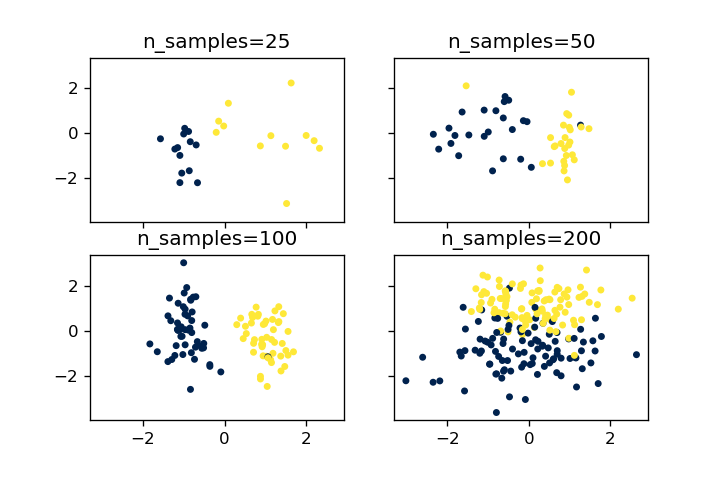
n_samples
n_samplesを変化させることでサンプル数を変えることができます。
n_features
n_featuresを変えることデータセットの列数を変えることができます。
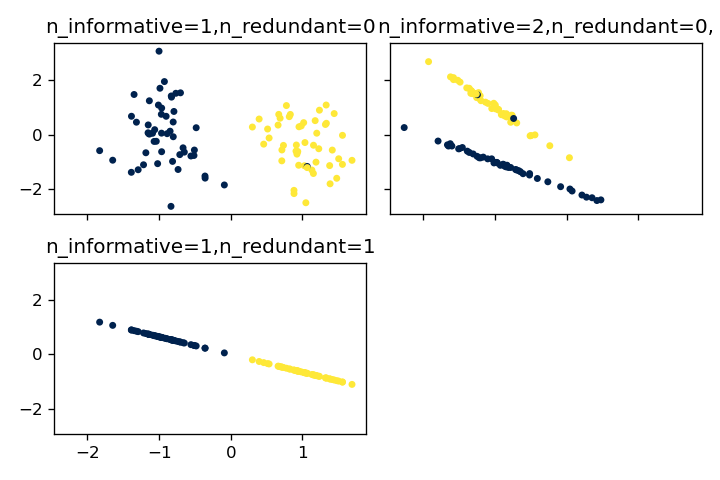
n_informative & n_redundant
n_informativeパラメータは相関が強い特徴量の数を指定し、n_redundantパラメータはn_informativeで指定した特徴量と線形結合になる特徴量の数を表します。
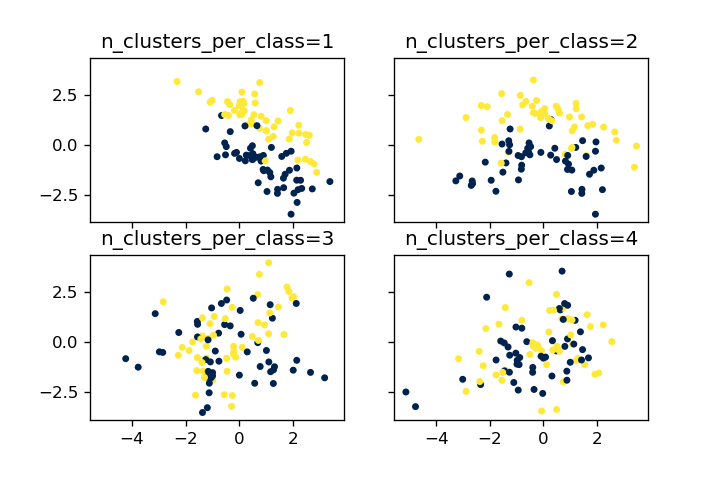
n_clusters_per_class
n_clusters_per_classは1クラスあたりのクラスターの数となります。
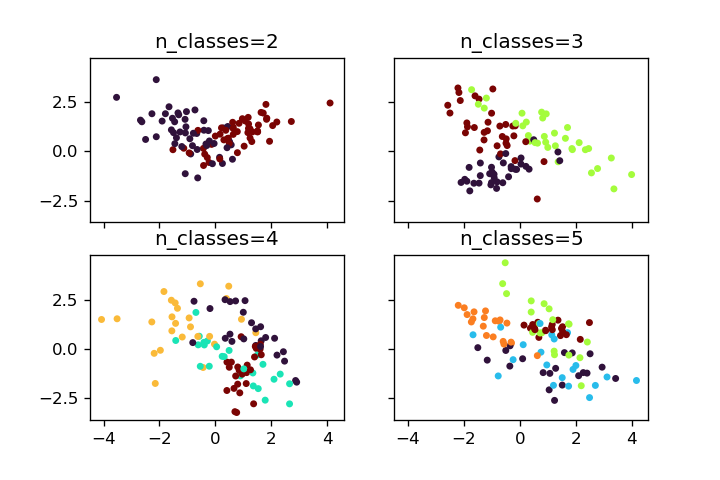
n_classes
n_clustersはクラス数です。
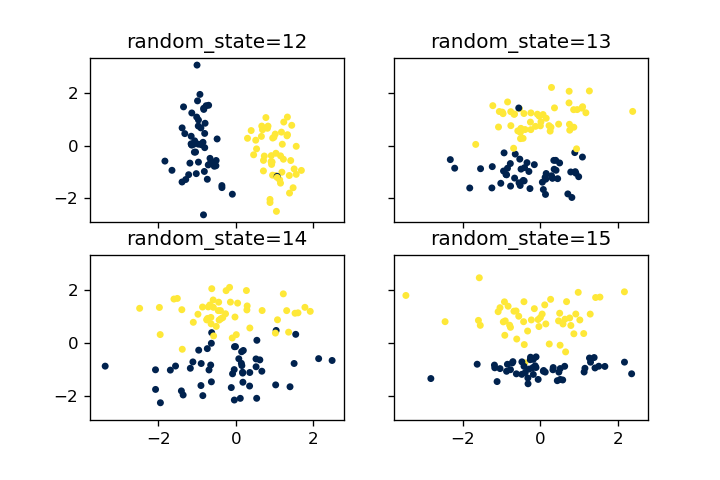
random_state
random_stateを変えることで再現可能な乱数を生成することができます。
weights
weightsをリスト形式で設定することでデータポイント数の比率を変えることができます。

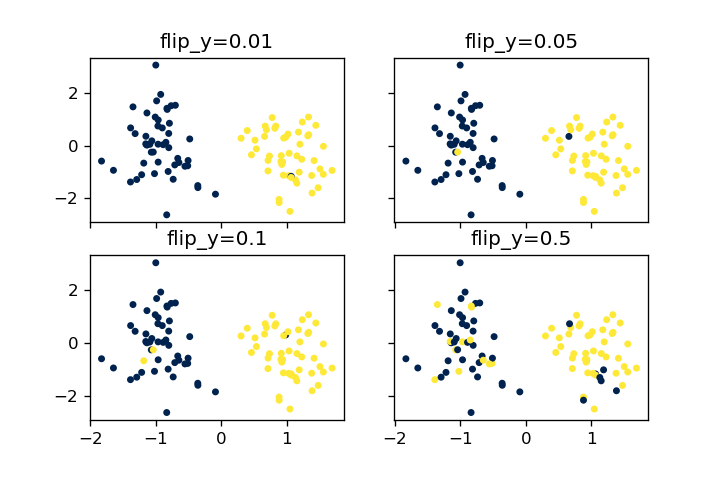
flip_y
flip_yは、エラー生成のためにデータポイントのラベルを入れ替える機能です。0.1を設定すると10%のデータのラベルが入れ替わります。デフォルト値は0.01です。
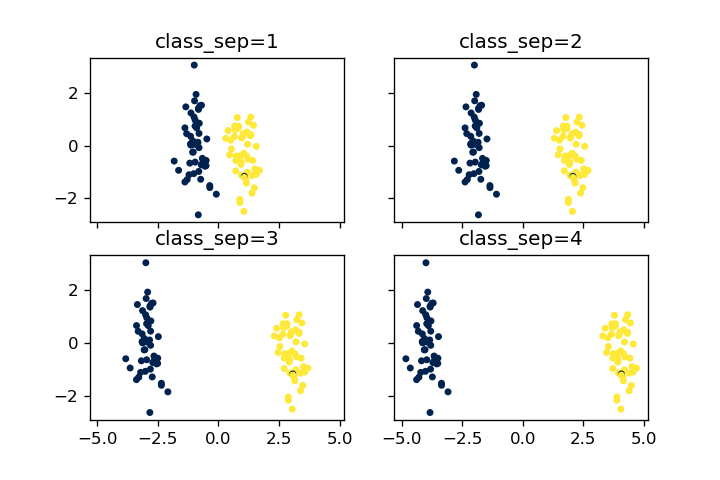
class_sep
値を大きくすると、クラス間がより分離するようになります。
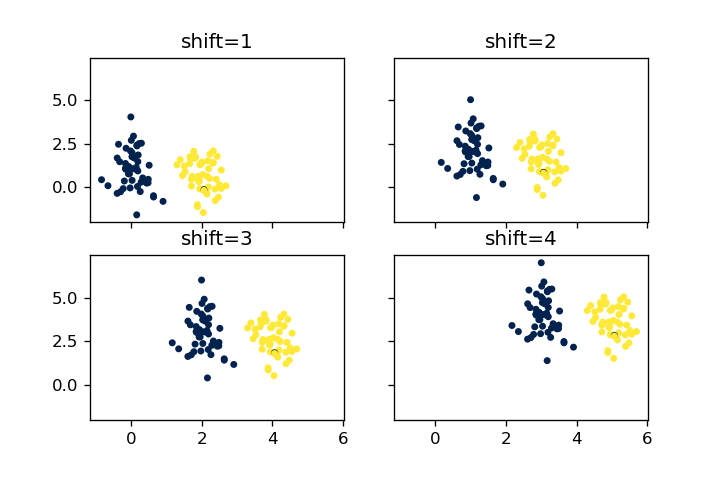
shift
shiftの値を全てのデータに加えることになります。
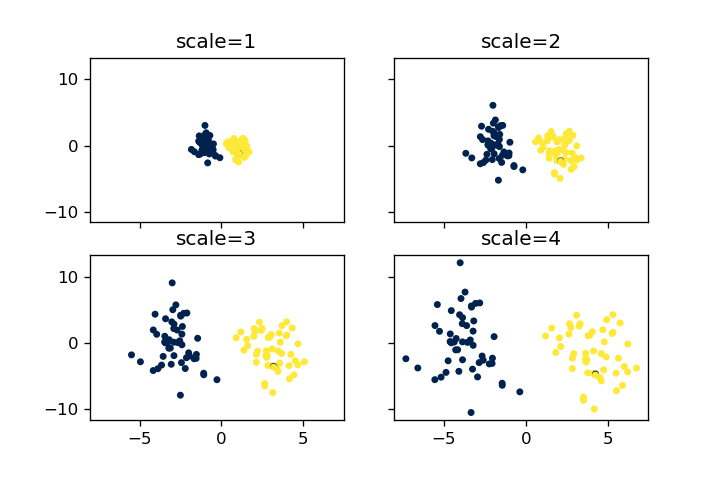
scale
scaleの値を全てのデータに乗ずることになります。
shuffle
shuffleをFalseとすることでラベルがソートされたデータを得ることができます。デフォルト値はTrueです。
コードをダウンロード(.pyファイル) コードをダウンロード(.ipynbファイル)まとめ
scikit-learnのmake_classification関数は、分類アルゴリズムのテスト用データを効率的に生成できるツールです。パラメータを調整することで、様々な複雑さや特性を持つデータセットを作成でき、機械学習モデルの開発と評価に非常に有用です。
参考


コメント