はじめに
このページでは、scikit-learnライブラリの
make_gaussian_quantiles関数を使用して、等方性なガウス分布に従うデータを生成する方法とその応用について説明します。異なるパラメータ設定が生成データにどのような影響を与えるかを詳しく解説していきます。
解説
モジュールのインポートなど
バージョン
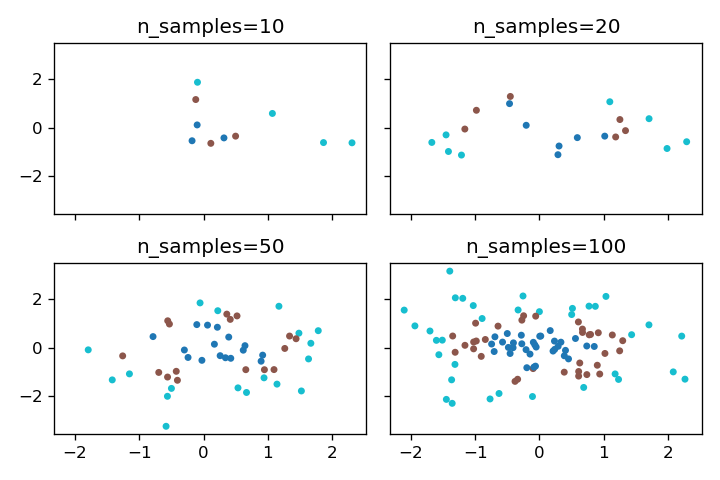
n_samples
パラメータn_samplesの値を変更することで、生成されるサンプル数を調整できます。
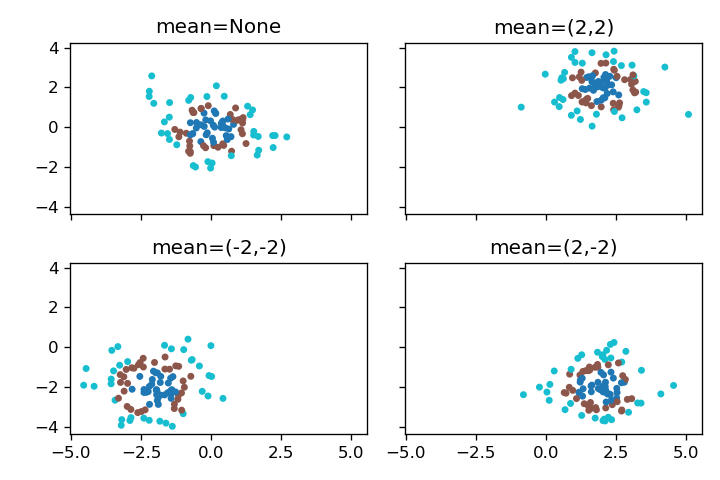
mean
分布の平均値をタプル(例:(2,2))で指定できます。None を指定した場合は、デフォルト値の(0,0)が使用されます。
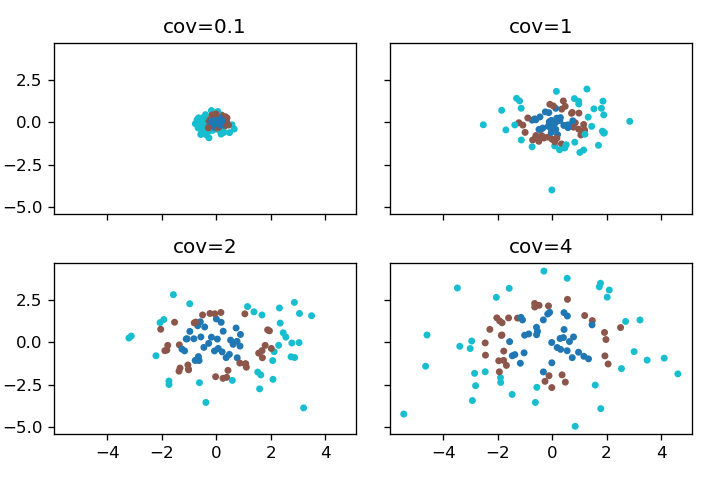
cov
共分散行列は、この値に単位行列を乗じたものになります。
n_features
パラメータn_featuresの値を変更することで、生成されるデータの次元数(特徴量の数)を調整できます。
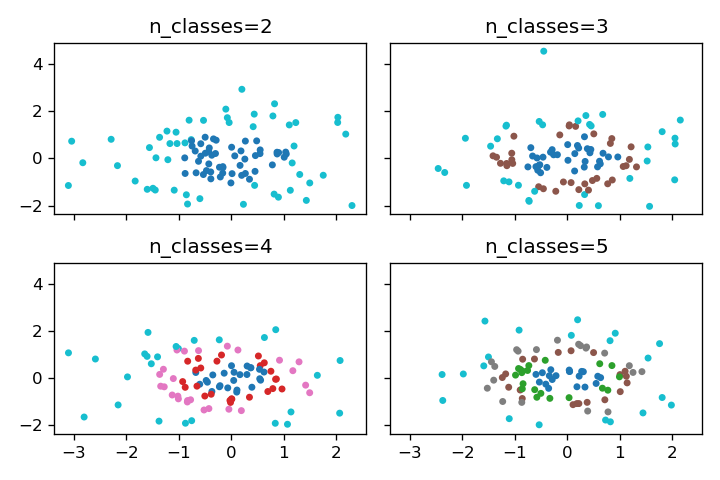
n_classes
パラメータn_classesの値を変更することで、生成されるデータのクラス数を調整できます。
random_state
パラメータrandom_stateを設定することで、再現性のある乱数生成が可能になります。
shuffle
パラメータshuffleをFalseに設定することで、ラベルがソートされたデータを得ることができます。デフォルト値はTrueです。
コードをダウンロード(.pyファイル) コードをダウンロード(.ipynbファイル)参考

make_gaussian_quantiles
Gallery examples: Multi-class AdaBoosted Decision Trees Two-class AdaBoost
scikit-learn

コメント