はじめに
sklearnのdatasets.make_swiss_rollでロールケーキ状に分布した3次元データを作成することができる。ここでは各種パラメータが生成するデータに及ぼす影響について説明する。
scikit-learnのdatasets.make_swiss_roll関数は、機械学習アルゴリズムをテストするための人工的な3次元データセットを生成するツールです。特に次元削減アルゴリズムの性能評価に広く利用されています。
解説
モジュールのインポートなど
バージョン
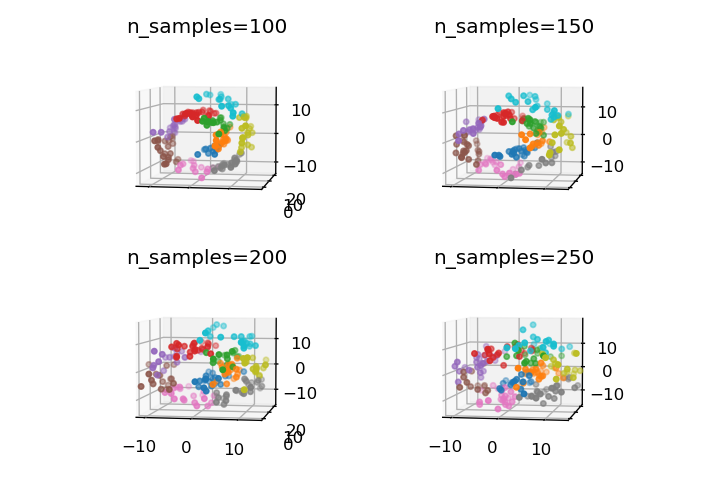
n_samples
生成するサンプル数を指定します。デフォルトは100で、この値を大きくするとより密度の高いデータセットが生成されます。
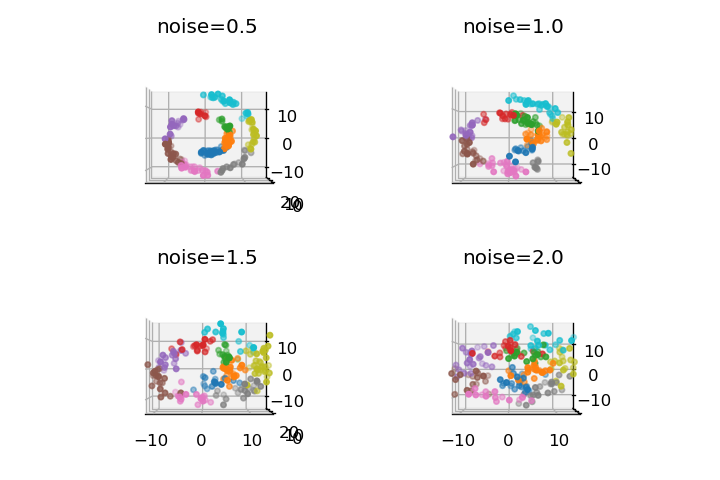
noise
データにランダムノイズを追加する量を指定します。デフォルトは0.0(ノイズなし)ですが、実データをシミュレーションする場合は適度なノイズを加えることが有効です。
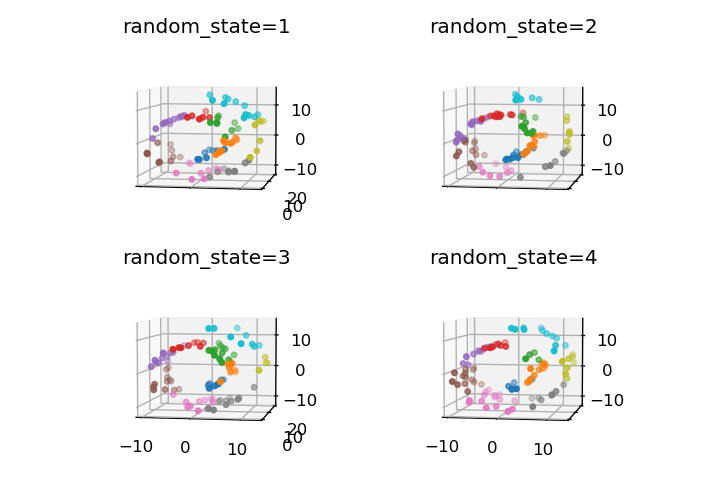
random_state
乱数生成のシード値です。同じ値を設定すると、毎回同じデータセットが生成されるため、実験の再現性が確保できます。
参考

make_swiss_roll
Gallery examples: Hierarchical clustering with and without structure Swiss Roll And Swiss-Hole Reduction
scikit-learn.org

コメント