はじめに
データ分析において、カテゴリー別のデータ分布を視覚化することは非常に重要です。Seabornライブラリは、このような視覚化を簡単かつ美しく実現するための強力なツールを提供しています。本記事では、特にカテゴリーデータの分布を表現するための3つの主要なプロット関数(barplot、countplot、pointplot)について詳しく解説します。
コード
解説
モジュールのインポートなど
データの読み込み
3/12〜14の名古屋と松山の気象データを下記サイトから読み込みます。

DataFrameの結合と列の追加
pd.concatでデータフレームを結合した後、新たな列データ[‘loc’]を追加します。np.tileは同じ要素を持つ配列を作成する関数で、データフレームの長さと同じサイズの配列を追加しました。名古屋のデータのDataFrameは下記のようになります(上位5行のみ表示)。
| 時 | 現地 | 海面 | 降水量(mm) | 気温(℃) | 露点温度(℃) | 蒸気圧(hPa) | 湿度(%) | 風速 | 風向 | 日照時間(h) | 全天日射量(MJ/㎡) | 降雪 | 積雪 | 天気 | 雲量 | 視程(km) | loc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1011.6 | 1018.5 | — | 7.5 | -0.4 | 5.9 | 57 | 3.8 | 北西 | NaN | NaN | — | — | NaN | NaN | NaN | nagoya |
| 1 | 2 | 1012.3 | 1019.2 | — | 7.4 | -0.8 | 5.8 | 56 | 4.8 | 北西 | NaN | NaN | — | — | NaN | NaN | NaN | nagoya |
| 2 | 3 | 1012.6 | 1019.6 | — | 7.1 | -1.1 | 5.6 | 56 | 4.3 | 西北西 | NaN | NaN | — | — | NaN | 1 | 25.0 | nagoya |
| 3 | 4 | 1013.1 | 1020.1 | — | 6.5 | 0.0 | 6.1 | 63 | 3.1 | 北西 | NaN | NaN | — | — | NaN | NaN | NaN | nagoya |
| 4 | 5 | 1013.8 | 1020.8 | — | 5.9 | 0.7 | 6.4 | 69 | 3.2 | 北西 | NaN | NaN | — | — | NaN | NaN | NaN | nagoya |
松山のデータも同様に処理します。
| 時 | 現地 | 海面 | 降水量(mm) | 気温(℃) | 露点温度(℃) | 蒸気圧(hPa) | 湿度(%) | 風速 | 風向 | 日照時間(h) | 全天日射量(MJ/㎡) | 降雪 | 積雪 | 天気 | 雲量 | 視程(km) | loc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1016.9 | 1021.2 | — | 6.0 | 0.6 | 6.4 | 68 | 2.7 | 東 | NaN | NaN | — | — | NaN | NaN | 20.0 | matsuyama |
| 1 | 2 | 1017.5 | 1021.8 | — | 4.8 | 0.2 | 6.2 | 72 | 1.3 | 北東 | NaN | NaN | — | — | NaN | NaN | 20.0 | matsuyama |
| 2 | 3 | 1017.5 | 1021.8 | — | 4.7 | -0.3 | 6.0 | 70 | 0.9 | 東北東 | NaN | NaN | — | — | NaN | NaN | 20.0 | matsuyama |
| 3 | 4 | 1017.5 | 1021.8 | — | 4.8 | -0.6 | 5.9 | 68 | 1.4 | 東北東 | NaN | NaN | — | — | NaN | NaN | 20.0 | matsuyama |
| 4 | 5 | 1018.2 | 1022.5 | — | 4.1 | -0.5 | 5.9 | 72 | 0.8 | 北東 | NaN | NaN | — | — | NaN | NaN | 20.0 | matsuyama |
DataFrameの合体
各データフレームを結合し、データをひとまとめにします。
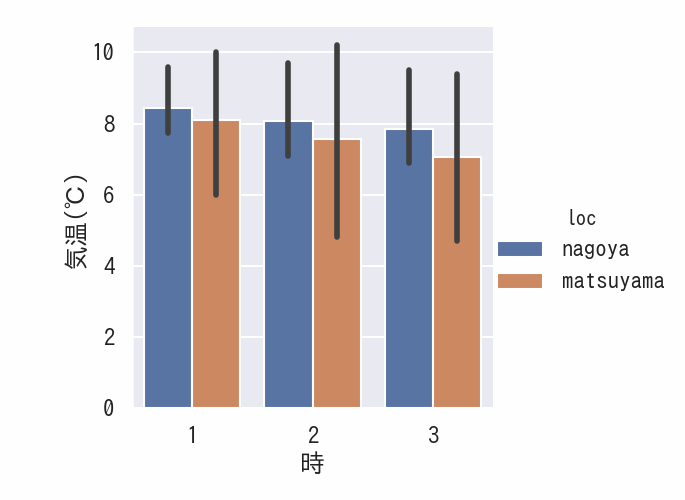
平均気温をエラーバー付き棒グラフで表示
このグラフでは、”時”をx軸、”気温(℃)”をy軸とした棒グラフを作成しています。hue=”loc”パラメータにより、各場所ごとに平均値と信頼区間が計算され、別々の棒として表示されます。また、data=df.loc[df.時 <4]の条件指定により、1時から3時までのデータのみを分析対象としています。いた。
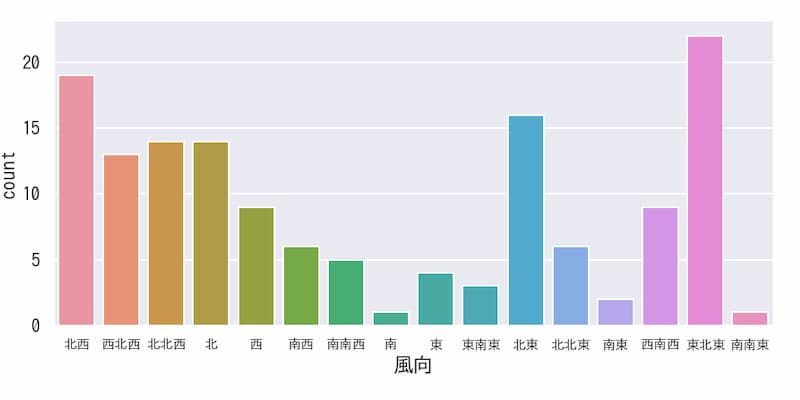
kind=”count”による要素数の棒グラフ
kind=”count”パラメータを使用すると、選択したカテゴリー内の要素数をカウントし、棒グラフで表示できます。この例では風向きごとの出現頻度を計測して可視化しています。軸ラベルの重なりを防止するため、aspect=2を設定して横長のグラフ形式にしました。
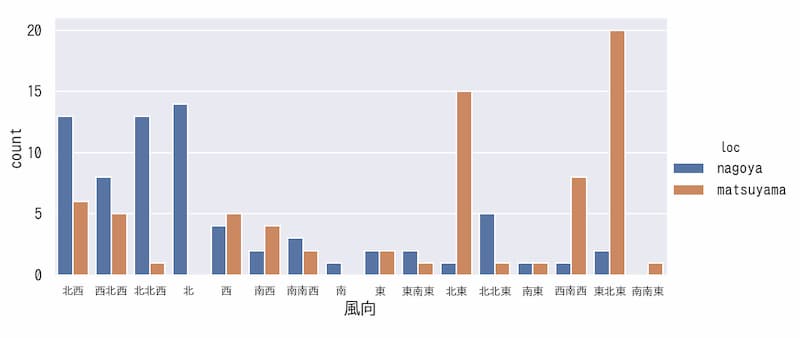
hueを用いたcountplot
hueに’loc’を設定すると、場所ごとの要素数を計測することができます。
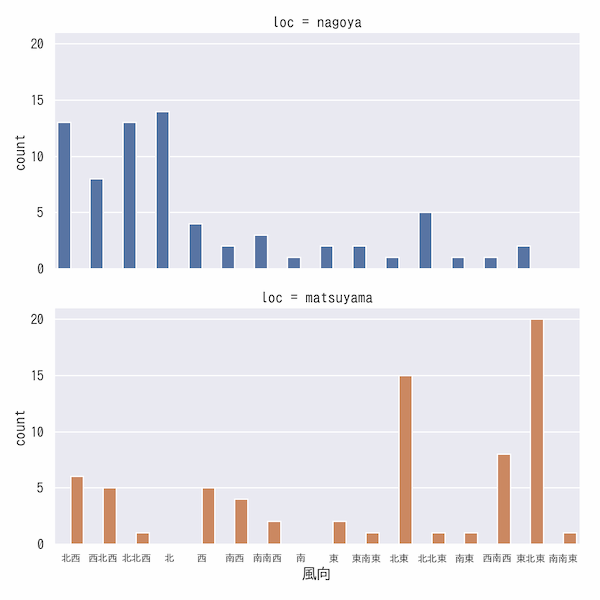
hueとrowを用いたcountplot
rowを設定することで、上下に別れて表示されます。
折れ線グラフの表示
kind=”point”によりエラーバー付きの折れ線グラフとなります。
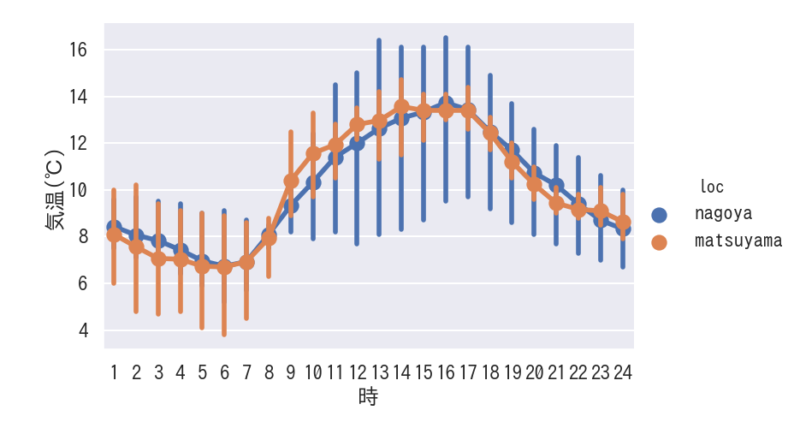
折れ線グラフ マーカーと線のスタイルの変更
markers=[“s”, “^”], linestyles=[“–“, “:”]のようにリストで設定することで、グラフにスタイルが反映されます。
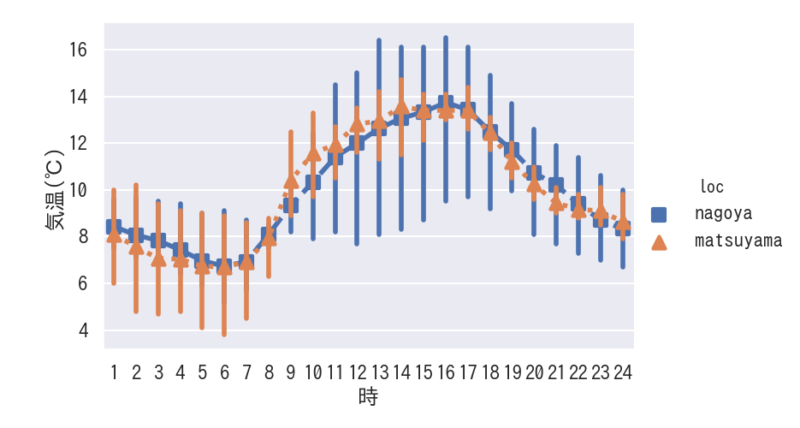
まとめと注意点
Seabornのbarplot、countplot、pointplotを使うことで、カテゴリーデータの分布を効果的に視覚化できることを学びました。各プロットタイプの特徴をまとめると:
- barplot:カテゴリー別の数値変数の統計量(平均値など)と信頼区間を表示
- countplot:カテゴリー変数の各値の出現回数を表示
- pointplot:カテゴリー間の変化や傾向を折れ線グラフで表示
これらのプロットを使用する際の注意点としては:
- データ量が少ない場合、信頼区間が広くなり解釈が難しくなることがあります。
- カテゴリーが多すぎると、グラフが読みにくくなります。必要に応じてカテゴリーをグループ化しましょう。
- 色分けによるグループ化は効果的ですが、3つ以上のグループになると識別が難しくなることがあります。
- 適切な推定量(平均値、中央値など)を選択することで、外れ値の影響を考慮できます。
以上の点に注意しながら、データの特性に合わせて適切なプロットタイプを選択することで、より効果的なデータ可視化が可能になります。
10. 参考資料


コメント