はじめに
データ分析や科学計算において、実験データや観測データを数学的モデルで近似することは非常に重要です。多項式モデルは、そのようなデータフィッティングの基本的かつ強力な手法の一つです。本記事では、Python用の非線形最小二乗法ライブラリである「lmfit」を使って、データを多項式関数でフィッティングする方法について詳しく解説します。
コード
解説
モジュールのインポートなど
バージョン
データの生成
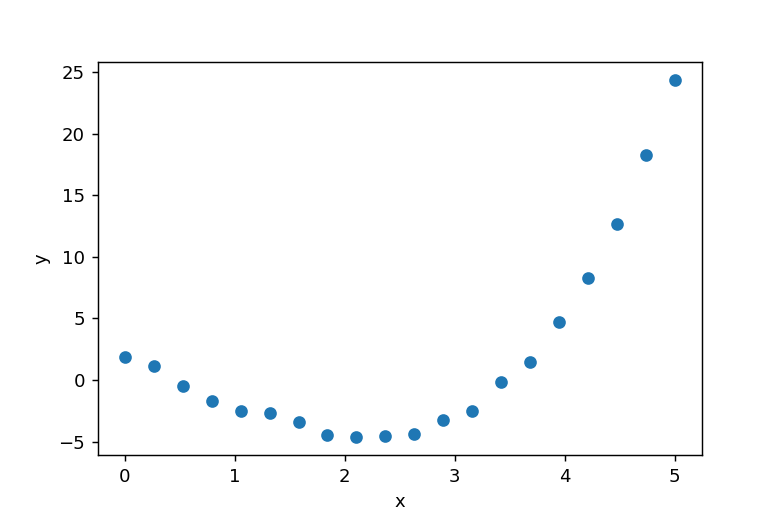
yデータは関数f(x,a,b,c,d)で定義して作成します。乱数生成には rng = default_rng() を使用し、rng.random(20) でランダムノイズを生成してyデータに加えます。xとyの関係を図示すると以下のようになります。
モデルの定義
lmfit.models モジュールの
PolynomialModel をモデル関数として使用します。ここでは degree=3 を指定して3次式をモデルとしました。なお、設定可能な次数の最大値は7です。
初期パタメータの推定
model.guess(y, x=x)を使用して、上図のデータを3次関数で近似するためのフィッティングパラメータの初期値を推定します。推定されたパラメータ(params)は以下のようになります。
カーブフィット
model.fit(y, params, x=x)により、カーブフィッティングを実行します。
フィッティング結果の表示
print(result.fit_report())により、フィッティングの結果を見ることができます。
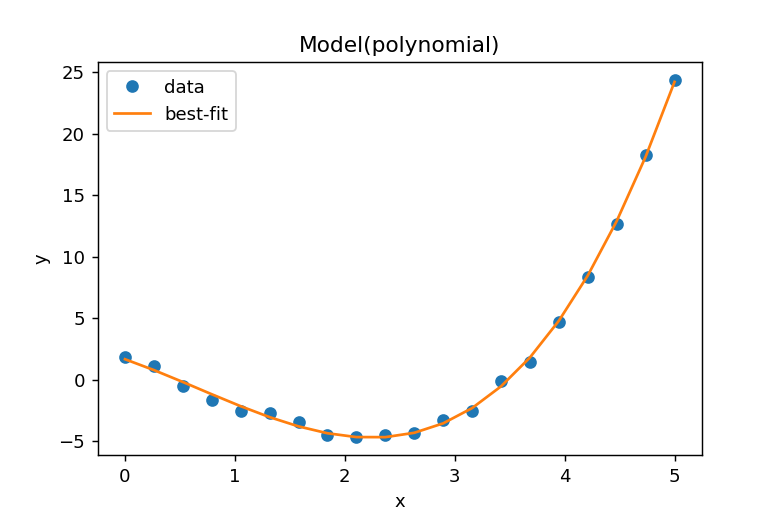
result.plot_fit()によりデータとフィッティングカーブが表示されます。
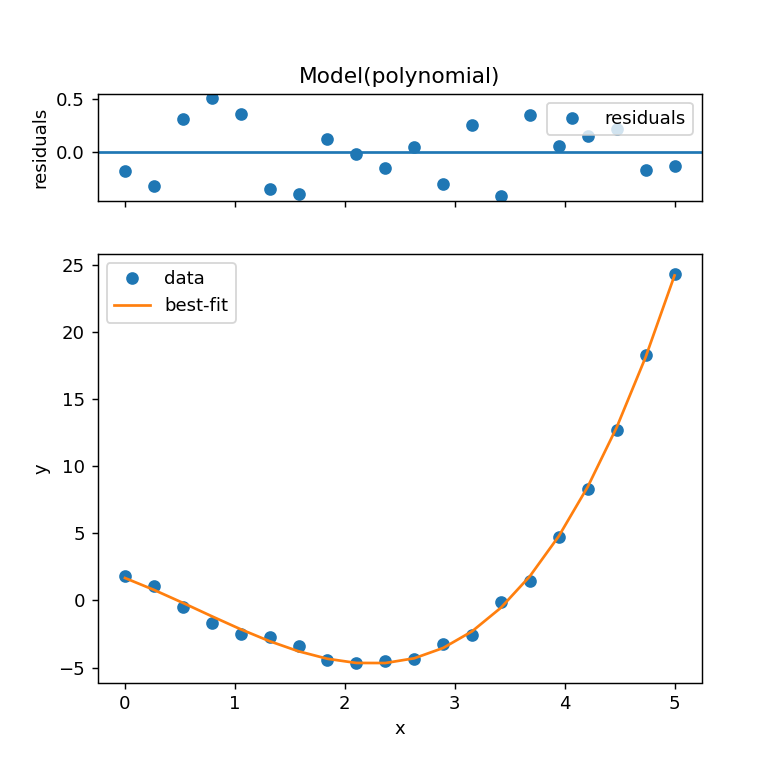
result.plot()とすることで残差とともにフィッティング結果が表示されます。
参考

Built-in Fitting Models in the models module — Non-Linear Least-Squares Minimization and Curve-Fitting for Python
lmfit.github.io


Random Generator — NumPy v2.4 Manual
numpy.org
コメント