はじめに
本記事では、scikit-learnのmake_blobs関数を使って分類モデルのテスト用データを生成する方法を解説します。この関数はガウス分布に従ったデータポイントを生成し、クラスタの数、特徴量の次元数、分散などのパラメータを調整することで、分類問題に適したデータセットを簡単に作成できます。
解説
モジュールのインポートなど
バージョン
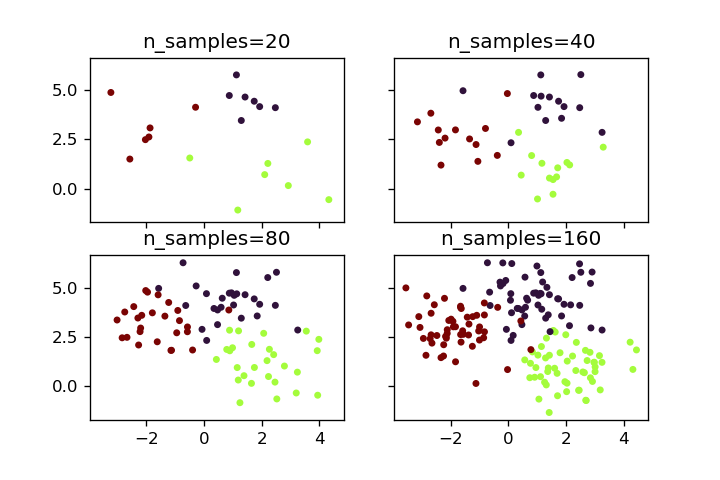
n_samples
n_samplesを変化させることでサンプル数を変えることができます。
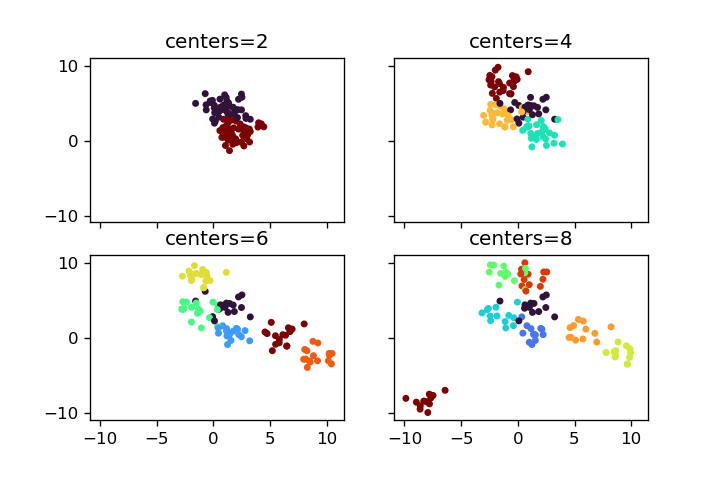
centers
centersを変えることでクラスターの数を変えることができます。
n_features
n_featuresパラメータを変更することで、データセットの列数(特徴量の次元数)を調整できます。
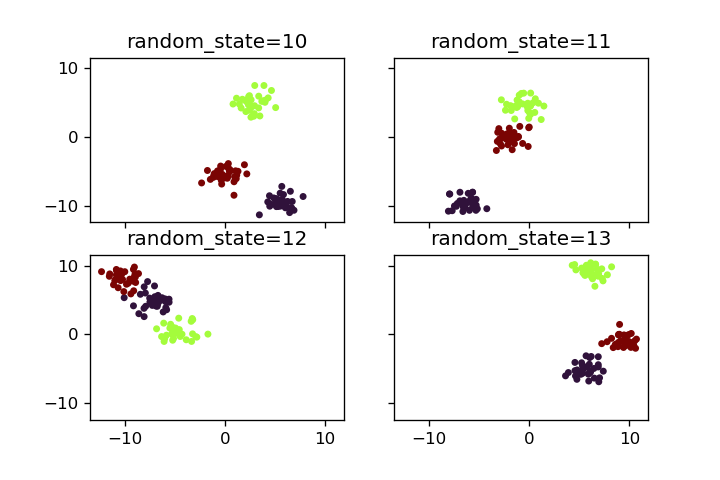
random_state
random_stateを変えることで再現可能な乱数を生成することができます。
cluster_std
cluster_stdを変えることでクラスターの分布の標準偏差を変えることができます。

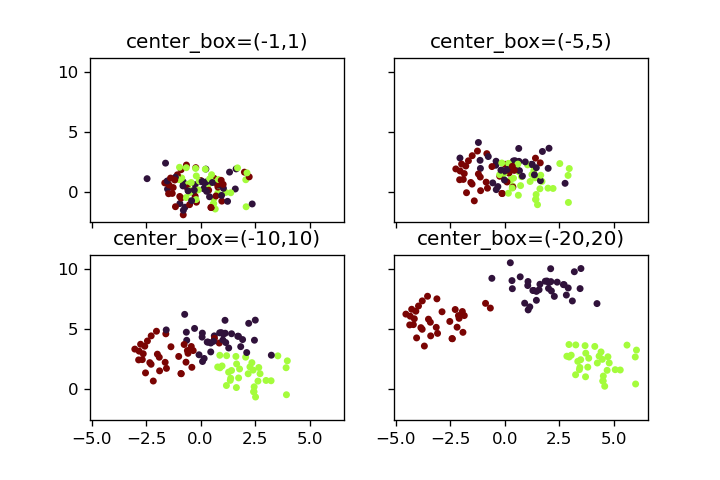
center_box
center_boxパラメータを調整することで、クラスター中心点の配置範囲を設定できます。
shuffle
shuffleパラメータをFalseに設定すると、ラベルがソートされたデータを取得できます。デフォルト値はTrueです。
return_centers
return_centersパラメータをTrueに設定すると、戻り値としてクラスターの中心座標も取得できます。
参考

make_blobs
Gallery examples: Probability calibration of classifiers Probability Calibration for 3-class classification Normal, Ledo...
scikit-learn

コメント