はじめに
データ分析において、カテゴリー別にデータの分布を視覚化することは非常に重要です。Pythonのseabornライブラリには、この目的に最適な2つの関数、stripplotとswarmplotが用意されています。これらの関数を使うことで、各カテゴリーのデータ点を散布図として表示し、分布の特徴を直感的に把握することができます。本記事では、これらの関数の使い方と違いについて解説します。
コード
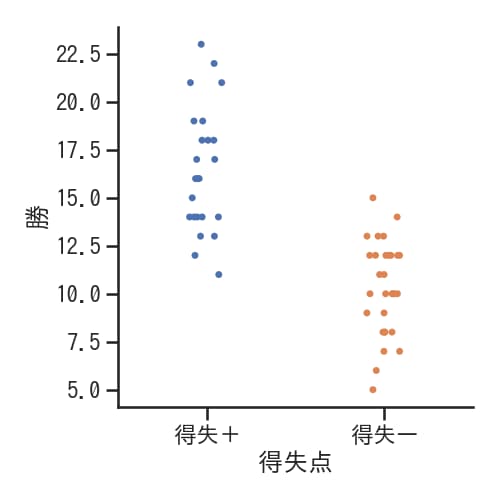
解説
モジュールのインポートなど
stripplotとswarmplotは、catplotのkindパラメータを指定することでプロットできます。catplotのデフォルト設定はstripplotとなっています。
データの読み込み
データは下記サイトから2017~2019シーズンのJ1の結果を取得し、pandasのDataFrameに変換しました。その後、作成した複数のDataFrameをpd.concatを使用して一つに結合しました。

新たな列データをDataFrameへ追加
得失点差のデータを用いて、チームをプラスとマイナスの2グループに分類します。プラスのチームには「得失+」、マイナスのチームには「得失-」というラベルを付けます。また、ランクについても同様の処理を行います。作成したDataFrameの最初の5行は以下のようになります。
| 順位 | Unnamed: 1 | Unnamed: 2 | 勝点 | 試合数 | 勝 | 分 | 敗 | 得点 | 失点 | 得失 | 平均得点 | 平均失点 | 得失点 | ランク | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | NaN | 横浜F・マリノス横浜FM | 70 | 34 | 22 | 4 | 8 | 68 | 38 | 30 | 2.0 | 1.1 | 得失+ | 上位 |
| 1 | 2 | NaN | FC東京FC東京 | 64 | 34 | 19 | 7 | 8 | 46 | 29 | 17 | 1.4 | 0.9 | 得失+ | 上位 |
| 2 | 3 | NaN | 鹿島アントラーズ鹿島 | 63 | 34 | 18 | 9 | 7 | 54 | 30 | 24 | 1.6 | 0.9 | 得失+ | 上位 |
| 3 | 4 | NaN | 川崎フロンターレ川崎F | 60 | 34 | 16 | 12 | 6 | 57 | 34 | 23 | 1.7 | 1.0 | 得失+ | 上位 |
| 4 | 5 | NaN | セレッソ大阪C大阪 | 59 | 34 | 18 | 5 | 11 | 39 | 25 | 14 | 1.1 | 0.7 | 得失+ | 上位 |
stripplotの表示
sns.catplot(x=”得失点”, y=”勝”, data=df)を使用すると、DataFrame(df)内の得失点カテゴリーごとに勝利データを散布図として視覚化できます。
jitterを変えた場合
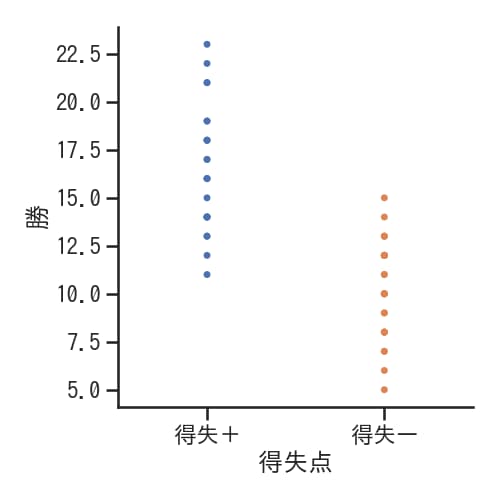
jitter=Falseとした場合
jitter=Falseを設定すると、データの横方向への広がりがなくなり、一直線上に散布図が表示されます。
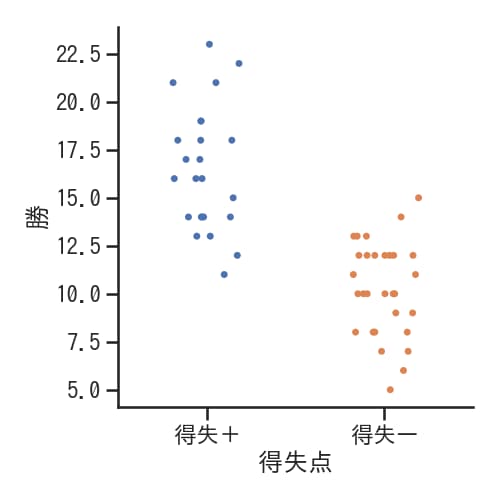
jitter=1/5とした場合
jitterパラメータに適切な値を設定することで、データの横方向への広がり具合を細かく調整できます。
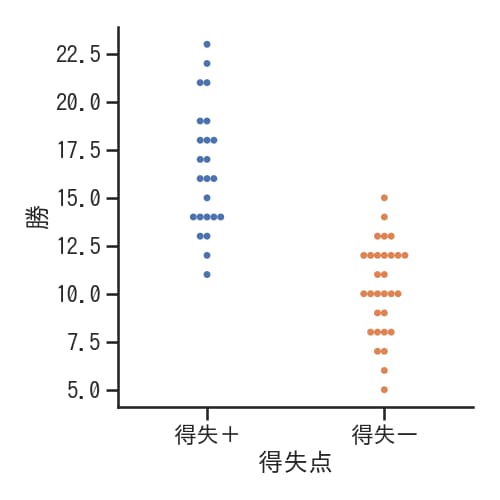
kind=”swarm”とした場合
kind=”swarm”パラメータを設定すると、データ点が重なり合うことなく配置され、データの分布をより明確に把握できます。
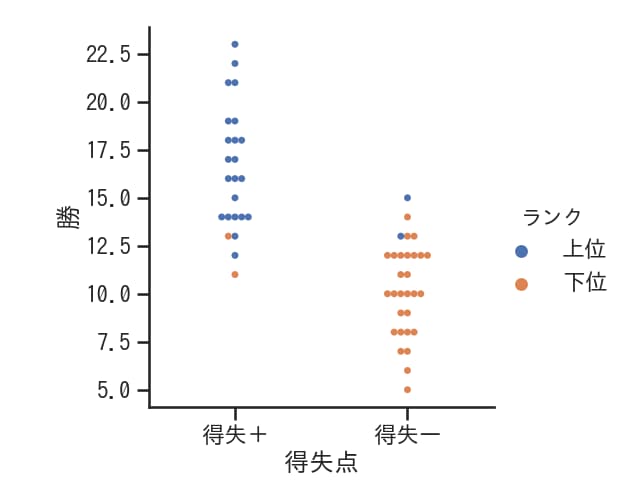
hueを設定した場合
hue=’ランク’パラメータを設定すると、ランクに応じてデータポイントが色分けされた散布図が表示されます。これにより、ランクごとのデータ分布を視覚的に比較できます。
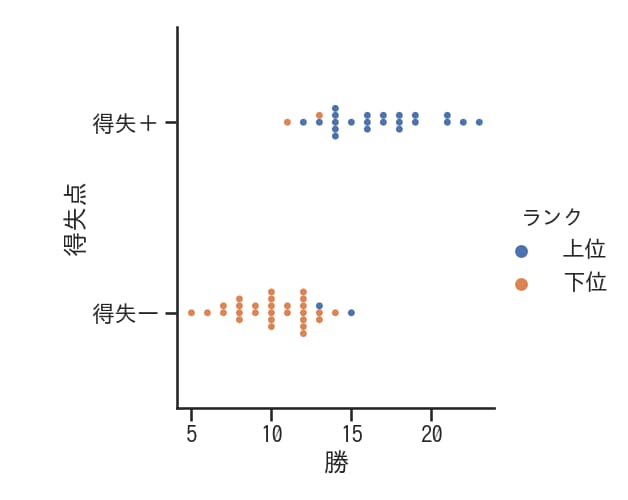
散布図の向きを水平方向にする
xとyのパラメータを入れ替えることで、水平方向に伸びた散布図を作成できます。
まとめ
seabornのstripplotとswarmplotは、カテゴリカルデータの分布を視覚化するための強力なツールです。stripplotはシンプルに各データ点を表示し、swarmplotはデータ点が重ならないように配置します。これにより、データの密度や分布の形状を把握しやすくなります。パラメータを調整することで、さまざまなニーズに合わせた可視化が可能です。データ分析の初期段階で分布を把握したい場合に、これらの関数を活用することをおすすめします。
参考




コメント