はじめに
本記事では、scikit-learnライブラリのKNeighborsClassifierを使用したk近傍法によるクラス分類の実装方法を解説します。make_blobs関数で生成した人工データセットを例として、k近傍法の基本原理、パラメータ設定、実装手順、性能評価について詳しく説明します。
k近傍法(KNN)とは
k近傍法(k-Nearest Neighbors、KNN)は、シンプルながら効果的な教師あり学習アルゴリズムの一つです。このアルゴリズムは、新しいデータポイントを分類する際に、特徴空間内で最も近い「k個」の既知のデータポイントの多数決によって分類を行います。
k近傍法の基本原理
k近傍法の基本的な考え方は次のとおりです:
- 新しいデータポイントと訓練データセット内の全ポイントとの距離を計算
- 最も距離が近いk個のデータポイントを選択
- それらk個のポイントの多数決で新しいデータポイントのクラスを決定
この方法は「近くにあるデータは似たような性質を持つ」という仮定に基づいています。
解説
モジュールのインポートなど
バージョン
データの生成
make_blobs関数を使用してデータを生成します。make_blobsの詳細については下記記事で解説しています。
cluster_std=.5を設定し、ばらつきの小さいデータ群を生成しました。
訓練用、テスト用データの分離
train_test_split関数を使用して、データを訓練用とテスト用に分割します。訓練データはX_train、y_trainとして、テストデータはX_test、y_testとして扱います。この例では、100個のデータポイントをtrain:test=75:25の比率で分割しています。
データの表示
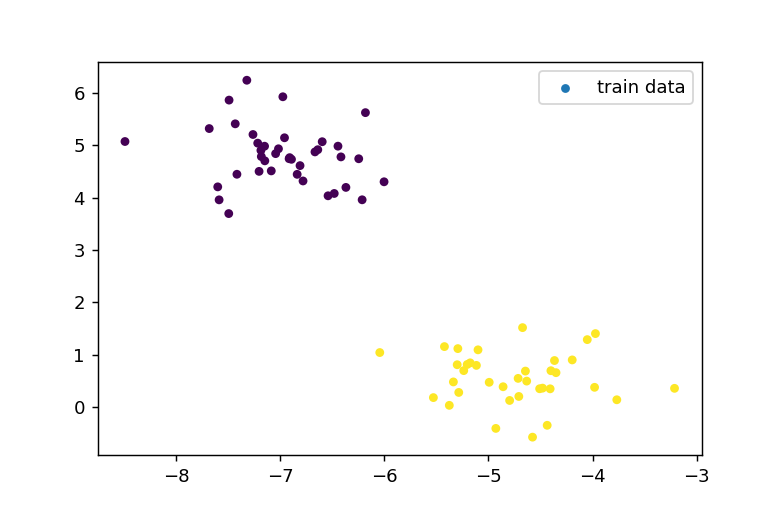
訓練用データの表示
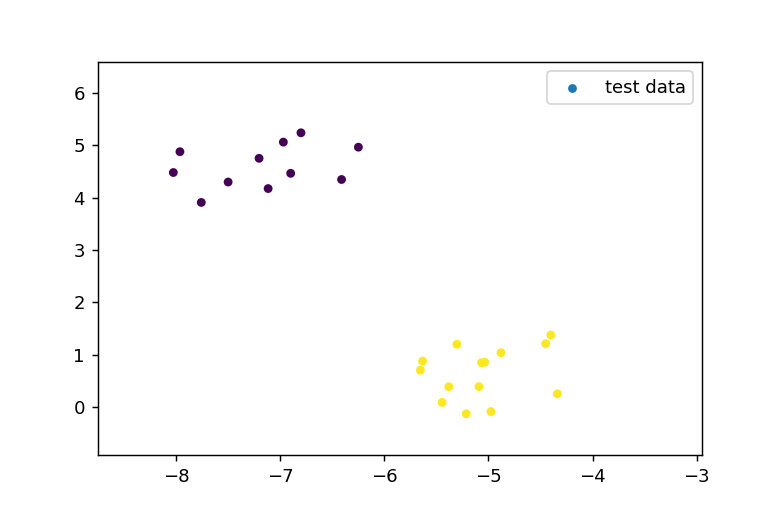
テスト用データの表示
k近傍法の適用
n_neighborsパラメータは、分類時に参照する近傍点の数を指定します。
neighbors.KNeighborsClassifierを使用して分類器を作成し、clf.fit(X_train, y_train)で訓練データを分類器に学習させます。clf.predict(X_test)メソッドを使用して、テストデータに対する予測を行います。
予測の正解率は1.0であるため、全てのデータが正しく分類されたことを示しています。
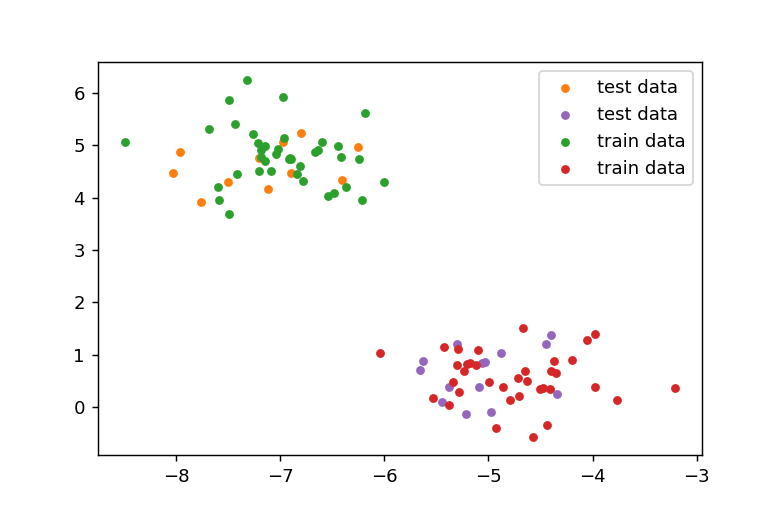
結果の表示
訓練用データの緑の点の近くにテスト用のオレンジのデータが位置し、赤の訓練用データの周辺に紫のテスト用データが存在していることが確認できます。
データのばらつきが大きい場合
データの作成
cluster_std=2.0と設定し、ばらつきの大きいデータを生成します。このとき、訓練用データとテスト用データは以下のようになります。
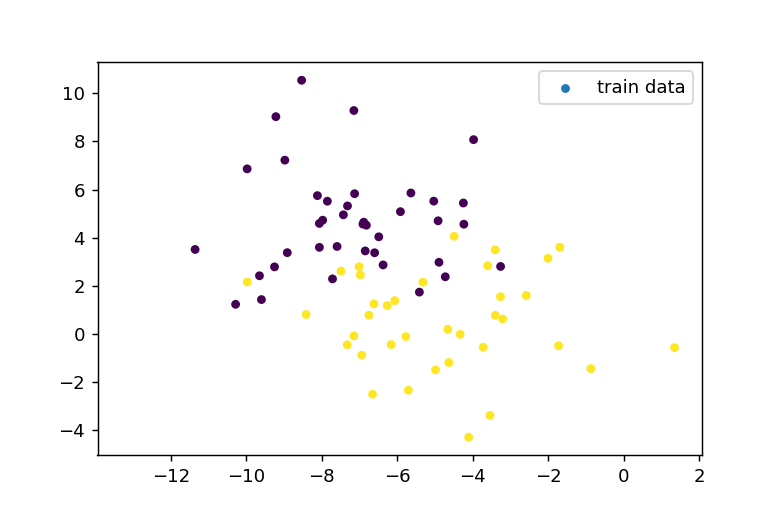
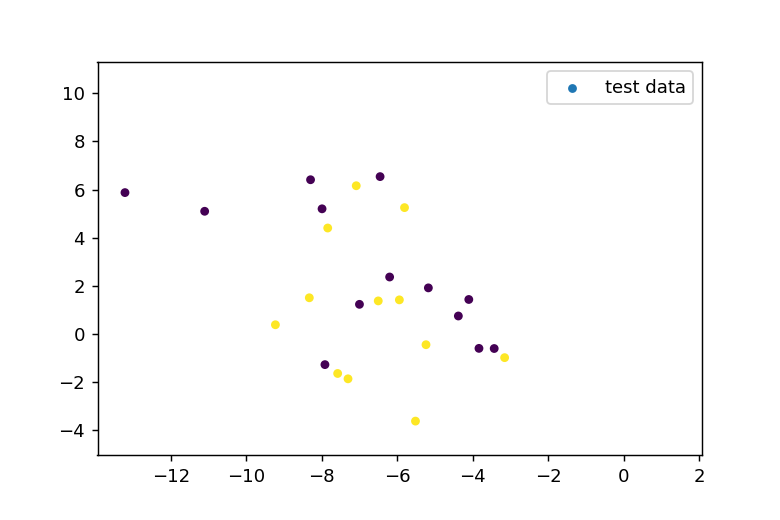
k近傍法の適用
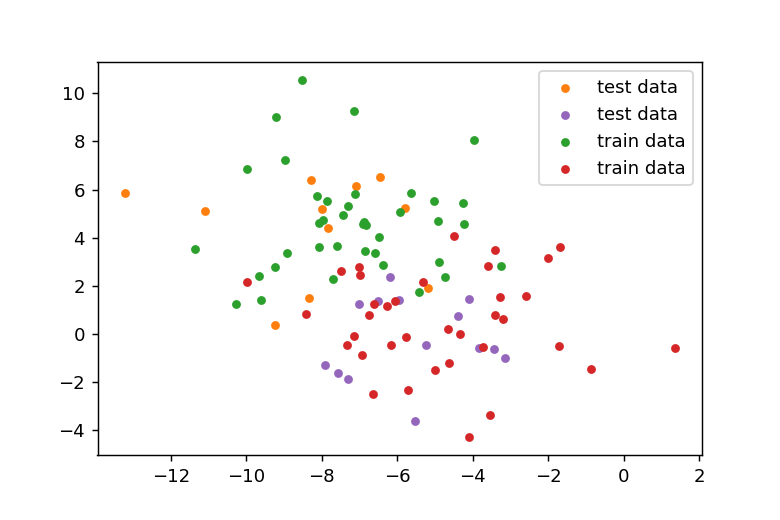
近傍点の数は先ほどと同じ3に設定して分類を実行しました。分類結果をプロットすると以下のようになります。
不正解なデータ点の確認
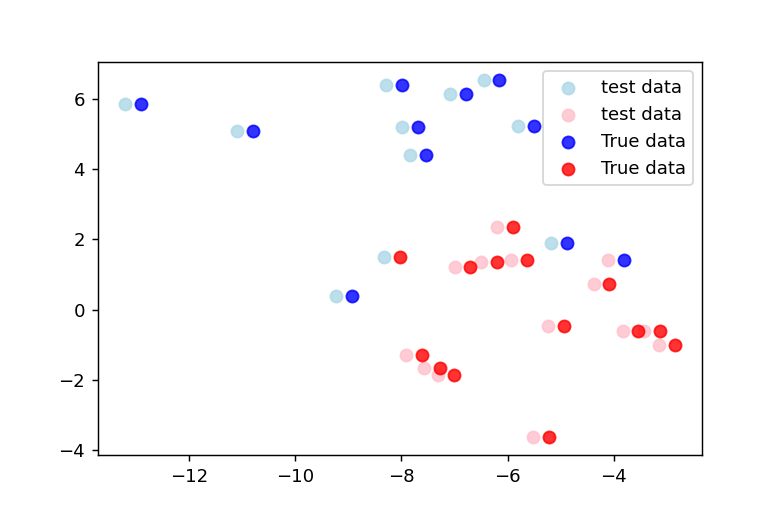
スコアは0.92なので、2つのデータが誤分類されていることになります。
不一致があるインデックスは、np.where関数を使用して特定できます。
正解データを予測データの右隣にプロットすると下図のようになります。予測が元データと異なる部分が2箇所あることが明確に確認できます。
まとめ
k近傍法は、シンプルながら多くの場合で効果的に機能する分類アルゴリズムです。特に小〜中規模のデータセットや、データの構造がそれほど複雑でない場合に適しています。パラメータが少なく直感的に理解しやすい一方、大規模データセットでの計算コストや次元の呪いには注意が必要です。
scikit-learnのKNeighborsClassifierを使えば、わずか数行のコードでk近傍法を実装でき、様々なデータ分析タスクに応用することができます。最適なパラメータを選択し、適切な前処理を行うことで、k近傍法の性能を最大限に引き出しましょう。
参考



コメント