はじめに
この記事では、NumPy、SciPy、lmfitを使用した線形近似の実行速度を比較します。np.polyfit、scipy.optimize.curve_fit、lmfitの3つの手法の性能評価を行い、matplotlibを用いてエラーバー付きの棒グラフで視覚的に表示します。
コード
解説
モジュールのインポート
バージョン
データの作成
np.arange(0, 10, 1)で0から9までの1刻み配列を作成し、yのデータにnp.random.rand(10)を使用してランダムなばらつきを付与します。
numpyのpolyfitの場合
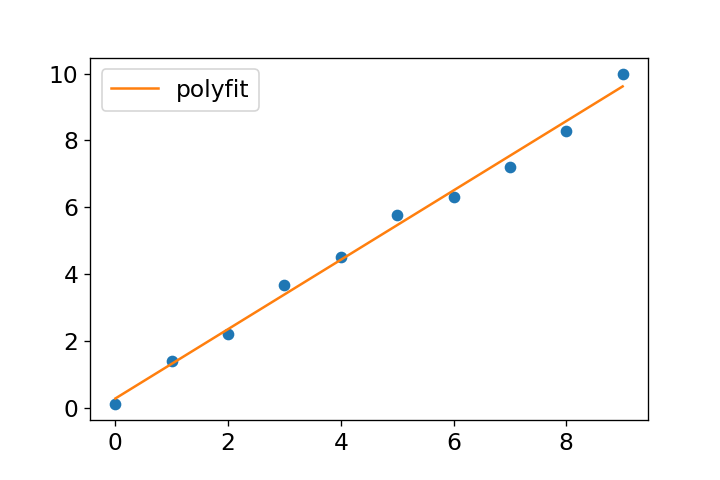
np.polyfit(x,y,1)を使用して1次式によるフィッティングの係数を求めます。これにより、y=ax+bの係数aとbを算出できます。
算出した係数pfをnp.polyval(pf,x)に適用することで、1次式に基づいたyデータを生成します。
元のデータと近似式を表示すると、下図のようになります。
numpy polyfitの実行時間の計測
%timeitで実行時間を計測します。
scipyのcurve_fitの場合
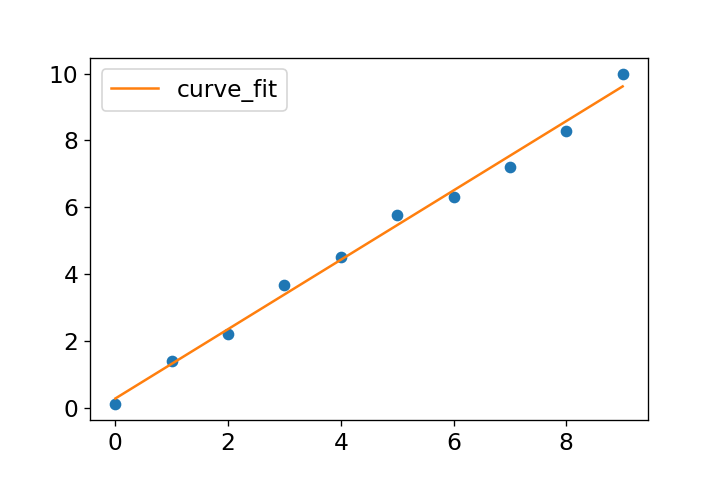
関数を定義し、curve_fitに関数、データ、初期値を渡すことで係数が求められます。np.polyval(popt, x)を使用して、係数poptによる1次式のyデータを生成できます。
データと近似式を表示すると下図のようになります。
なお、決定係数の求め方については下記記事で解説しました。

scipy curve_fitの実行時間の計測
%timeitで実行時間を計測します。
lmfitの場合
lmfitは非線形近似のための高レベルなインターフェイスで、より詳細な分析情報を取得できます。condaを使用してインストールする場合は、以下のコマンドを実行します。
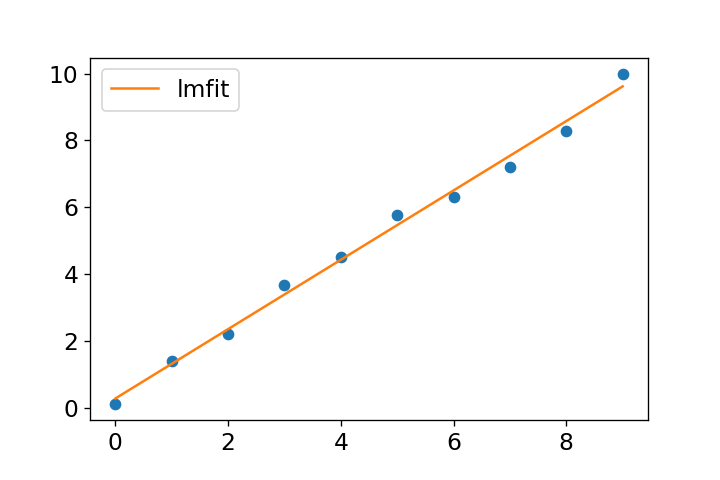
conda install -c conda-forge lmfitlmfitの基本的な使い方はcurve_fitと類似しており、モデルを定義し、初期値とデータを渡して近似を実行します。近似結果はresult.best_fitから取得できます。
データと近似式を表示すると、下図のようになります。
lmfitの実行時間の計測
%timeitで実行時間を計測します。
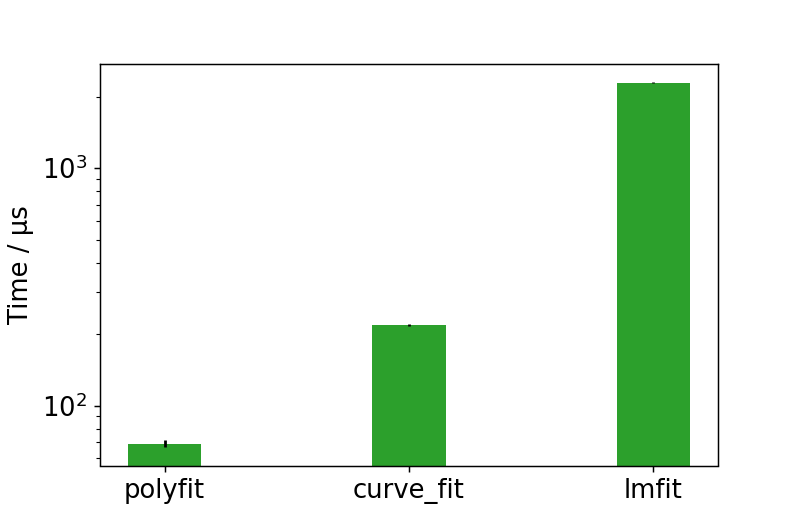
実行時間の比較
np.polyfitが最も高速であり、次いでcurve_fit、lmfitの順に実行時間が長くなります。
まとめ
本記事では、np.polyfit、curve_fit、lmfitの3つの手法による線形近似の実行速度を比較しました。それぞれの手法の特徴とパフォーマンスの違いを明らかにし、どのような状況でどの手法が適しているかについての知見を提供しました。適切な手法の選択は、データの特性や求める精度、計算効率によって異なることを示しました。
参考





コメント