はじめに
scikit-learnのKNeighborsClassifierを使用したk近傍法によるクラス分類と決定境界の可視化方法について解説します。sklearn.datasets.make_blobsで生成したデータセットを用いて、分類モデルの構築から決定境界の描画までの手順を紹介します。
解説
モジュールのインポートなど
バージョン
データの生成
make_blobsを使用してデータを生成します。make_blobsの詳細については下記記事で説明しています。
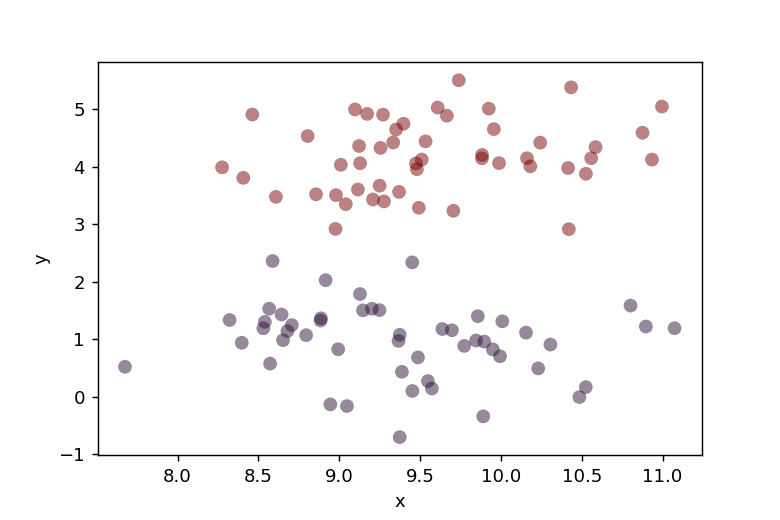
random_state=4を指定することで上下に明確に分離したデータ群を生成しました。生成されたデータを表示すると、以下のようになります。
格子状データの作成
決定境界を可視化するために、細かい間隔の格子状データをテストデータとして使用し、分類結果を塗りつぶし等高線で表示します。この例では、meshgrid関数とnp.arangeを使って間隔0.05の格子状データを作成します。
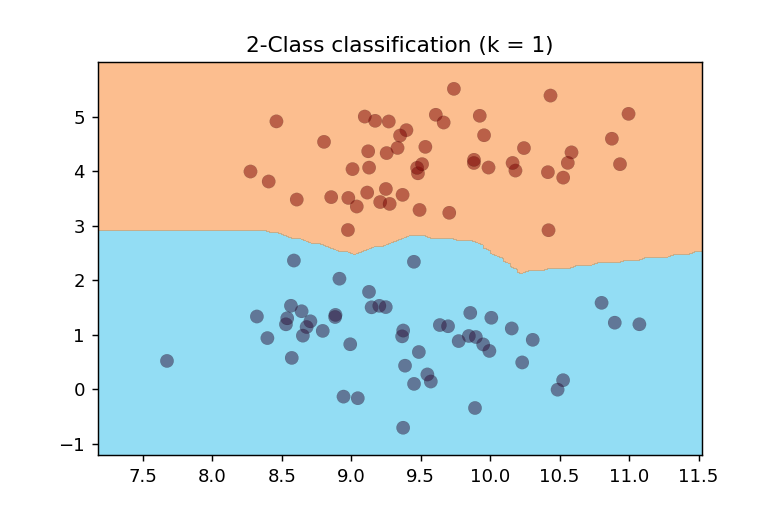
k近傍法(k=1)の適用
n_neighborsパラメータは、分類時に参照する近傍点の数を指定します。この例では1に設定しています。
neighbors.KNeighborsClassifierで分類器を作成し、clf.fit(X, y)を使って訓練データをモデルに学習させます。
学習したモデルに対し、clf.predict()メソッドでテストデータの予測を行います。テストデータとして、次のコード:
np.concatenate((xx.ravel()[:,np.newaxis], yy.ravel()[:,np.newaxis]),axis=1)
で生成したデータを使用します。このデータの形状は(12760, 2)となっています。
予測結果のZは1次元配列で返されるため、reshapeメソッドを使ってxxと同じ形状に変換します。
結果の表示
ax.contourf(xx, yy, Z, levels, cmap=”turbo”, alpha=0.5)を使用して、塗りつぶし等高線として決定境界を可視化できます。単に輪郭線のみを表示したい場合は、contourf関数の代わりにcontour関数を使用します。
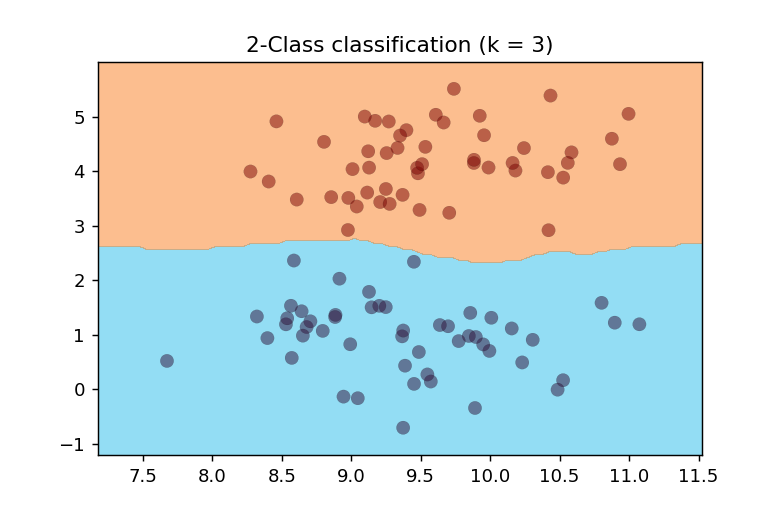
k=3の場合
近傍データ数を3とした時の決定境界は以下のようになります。
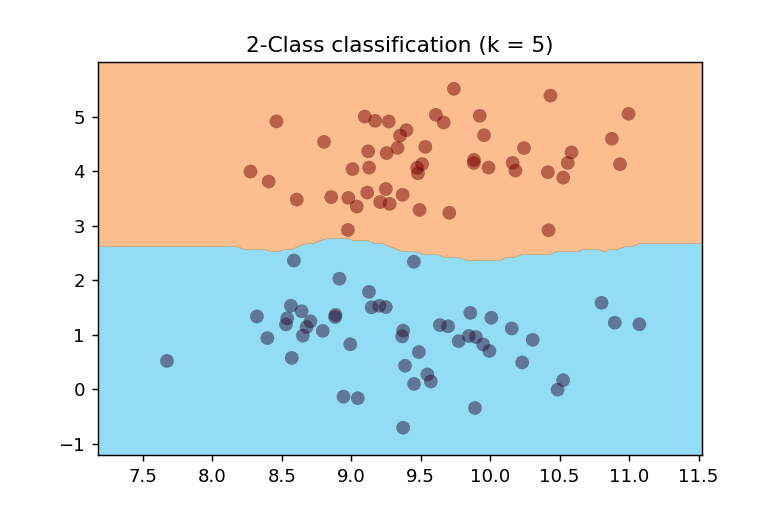
k=5の場合
近傍データ数を5とした時の決定境界は以下のようになります。
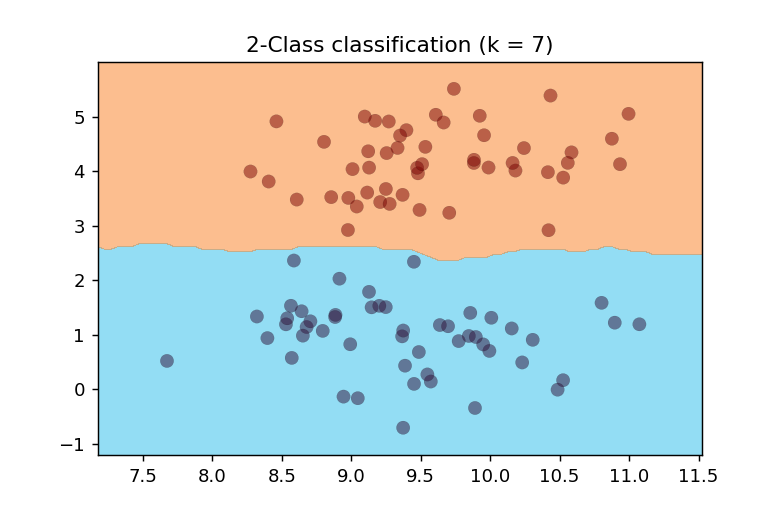
k=7の場合
近傍データ数を7とした時の決定境界は以下のようになります。
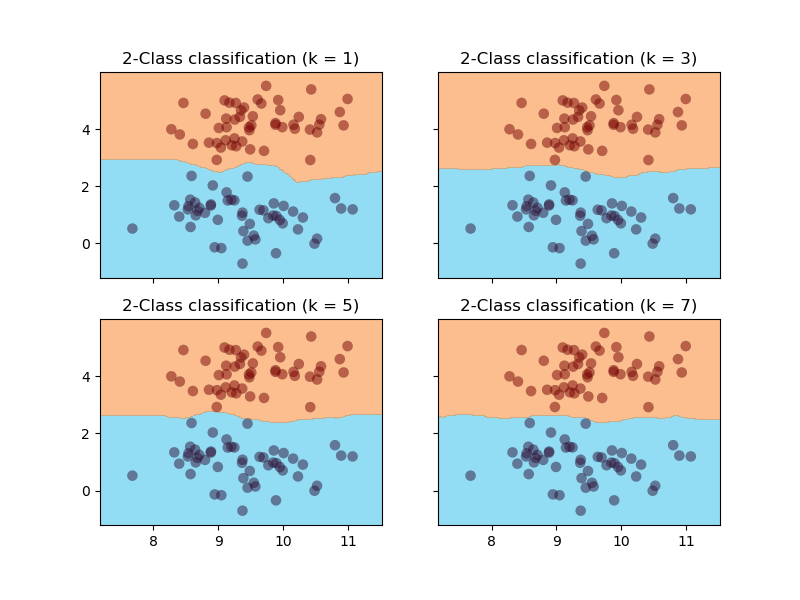
k=1,3,5,7の結果をまとめて表示
k=1,3,5,7の結果をまとめて表示すると以下のようになります。
まとめ
本記事では、scikit-learnのKNeighborsClassifierを用いたk近傍法によるクラス分類とその決定境界の可視化方法について解説しました。make_blobsによるデータ生成からモデルの構築、評価、そして決定境界の描画までの一連の流れを学ぶことで、k近傍法の基本的な理解と実装スキルを身につけることができます。
参考



コメント